前書き
この記事は、JSL(日本システム技研) Advent Calendar 2020 - Qiita 12/17の記事です!
AWS GlueのクローラをClassifier(分類子)のgrokパターン定義とともに使ってApacheログを解析する手順を、AWS CLIを用いた実例とともに説明します。 AWS Glueを使えば、ログを直接確認するだけではなく、データの抽出や変換、統計量などをETLスクリプトとして記述することができます。
環境
前提知識
実際の手順に入る前に、Classifier(分類子)の説明とCLIの使用例を説明します。
Classifier
分類子です。データの形式を定義します。クローラを動かす際、デフォルトでは対象のファイルの拡張子などからcsvやjsonを認識してくれているようです(明示的に、すでに用意されているClassifierを使うこともできます)。 またcsvの区切り文字などを指定して、カスタムのclassifierを作ることもできます。
今回は、正規表現を使ってclassifierをカスタムできるgrokを使用します。
公式資料はこの辺です。 Writing Custom Classifiers - AWS Glue
GrokPatternでは、デフォルトで用意されたパターンを使ってデータを抜き取ることができます。 自分で正規表現を書いてパターンを記述することもできます。CustomPatternsにパターンの一覧を渡すことで、GrokPattern側で利用することができるようになります。
# 全classifierの一覧([]で階層潰し。*はgrok以外もとりたいので。)
aws glue get-classifiers --max-items 10 --query "Classifiers[*].*.[Name,Classification][]"
# 単品。取れる情報は↑と変わらないっぽい。
aws glue get-classifier --name custom-csv-classifier
# createの例。
aws glue create-classifier
--grok-classifier 'Classification=custom-tsv,Name=my-classifier,GrokPattern="%{NOTTAB:no}\\t%{NOTTAB:name}\\t%{NOTTAB:age}",CustomPatterns="NOTTAB [^\\t]*"'
# jsonで表記するcreateの例
cat << EOS > tmp-classifier-grok.json
{
"Classification": "custom-tsv-special",
"Name": "my-classifier",
"GrokPattern": "%{NOTTAB:no}\\t%{NOTTAB:name}\\t%{NOTTAB:age}",
"CustomPatterns": "NOTTAB [^\\t]*"
}
EOS
aws glue create-classifier --grok-classifier file://tmp-classifier-grok.json
# 削除
aws glue delete-classifier --name custom-csv-classifier
# update-classifierもあるが今回は省略。
前準備(データの投入)
Athenaのドキュメントの例を今回は使わせていただくことにします。(grokの書きかたもこちらの通り。)
Querying Apache Logs Stored in Amazon S3 - Amazon Athena こちらのページから、以下のファイルをコピーして、S3の適当なパスにアップロードしておきます。
S3_BUCKET_NAME='your_bucket_name'
cat << EOS > access.log
198.51.100.7 - Li [10/Oct/2019:13:55:36 -0700] "GET /logo.gif HTTP/1.0" 200 232
198.51.100.14 - Jorge [24/Nov/2019:10:49:52 -0700] "GET /index.html HTTP/1.1" 200 2165
198.51.100.22 - Mateo [27/Dec/2019:11:38:12 -0700] "GET /about.html HTTP/1.1" 200 1287
198.51.100.9 - Nikki [11/Jan/2020:11:40:11 -0700] "GET /image.png HTTP/1.1" 404 230
198.51.100.2 - Ana [15/Feb/2019:10:12:22 -0700] "GET /favicon.ico HTTP/1.1" 404 30
198.51.100.13 - Saanvi [14/Mar/2019:11:40:33 -0700] "GET /intro.html HTTP/1.1" 200 1608
198.51.100.11 - Xiulan [22/Apr/2019:10:51:34 -0700] "GET /group/index.html HTTP/1.1" 200 1344
EOS
aws s3 cp access.log "s3://${S3_BUCKET_NAME}/log-resource-sample/access.log"
実際の手順
Databaseの作成
- この後の手順でクローラを起動し、テーブルを作成を行います。そのテーブルを保持するデータベースを作成しておきます。(これまでにつくったデータベースがあれば、それを利用してもOKです。)
cat << EOS > database-definition.json
{
"Name": "access-log-db",
"Description": "analyze access logs."
}
EOS
aws glue create-database --database-input file://database-definition.json
# 完了確認
aws glue get-database --name access-log-db
Classifierの作成
ログ解析に使うgrokのパターンも、Athenaのドキュメントで説明されている物をそのまま使用させていただきます。 Querying Apache Logs Stored in Amazon S3 - Amazon Athena
cat << EOS > tmp-classifier-grok.json
{
"Classification": "custom-log",
"Name": "access-log-classifier",
"GrokPattern": "^%{IPV4:client_ip} %{DATA:client_id} %{USERNAME:user_id} %{GREEDYDATA:request_received_time} %{QUOTEDSTRING:client_request} %{DATA:server_status} %{DATA: returned_obj_size}$"
}
EOS
aws glue create-classifier --grok-classifier file://tmp-classifier-grok.json
aws glue get-classifier --name access-log-classifier
crawlerの作成
- ロールの作成は省略します。
- こちらの記事で作成した
AWSGlueServiceRole-Tmp-Testロールと同じロールを作成すればOKです。- この後指定するS3バケットへのアクセス権限を付与しておきます。リンク先の記事を参照してください。
これまでの手順で作成したDatabaseとClassifierおよびロールに加え、クロール対象のS3パスを指定します. クロール対象を指定するjsonの書き方は、以下のようにして調べることができます。
# 1. ヘルプを開く aws glue create-crawler help # 2. cli-skeletonコマンドを叩く。(こちらの詳しい説明は省略します) aws glue create-crawler --generate-cli-skeleton
それでは実際の手順を進めていきます。
CRAWLER_ROLE=AWSGlueServiceRole-Tmp-Test
DATABASE_NAME=access-log-db
CLASSIFIER=access-log-classifier
S3_BUCKET_NAME='your_bucket_name'
# クロールターゲット(s3)の指定を示すjsonは少々長いため、一度ファイルに書き込む。
# 「前準備」の項目で作成したファイルへのパスを記載する。
cat << EOS > tmp.json
{
"S3Targets": [
{
"Path": "s3://${S3_BUCKET_NAME}/log-resource-sample",
"Exclusions": []
}
],
"JdbcTargets": [],
"DynamoDBTargets": [],
"CatalogTargets": []
}
EOS
# jsonが壊れていないか確認しておく。
python3 -m json.tool tmp.json
クローラを作成します。
AWS Tags in AWS Glue - AWS Glue
必須ではありませんがこの時タグをつけておくと良いです。
今回は詳しい説明は省きますが、タグをつけておくと後々検索や使用した料金などの分析、権限管理に役立ちます。
タグの形式はKey=Value,Key2=Value2というものであり、helpから確認することができます。
aws glue create-crawler \
--name grok-accesslog-crawler \
--role $CRAWLER_ROLE \
--database-name $DATABASE_NAME \
--description "character csv crawler" \
--classifiers $CLASSIFIER\
--targets file://tmp.json \
--tags Name=accesslog,Creation=cli
完了確認にはlist-crawlersコマンドが便利です。
このコマンドはcrawlerの名前だけをlistするので、出力が少なくすっきりしています。
# queryで、クローラにつけた名前の一部を利用して出力を絞るパターン
aws glue list-crawlers --query "CrawlerNames[?contains(@, 'accesslog')]"
[
"grok-accesslog-crawler"
]
タグをつけていれば、それを使った絞り込みもできます。一連のリソースに同じタグをつけておけば便利ですね。
# タグを使って出力を絞る例。
aws glue list-crawlers --tags Name=accesslog
{
"CrawlerNames": [
"grok-accesslog-crawler"
]
}
crawlerの情報確認
クローラの実行前に、クローラの詳しい情報を出力するコマンドを見ておきます。
# 特定のcrawlerの情報を出力する。 aws glue get-crawler --name grok-accesslog-crawler
特に、実行中のステータスをfilterして確認できるようにしておきます。
aws glue get-crawler --name grok-accesslog-crawler --query "Crawler.{NAME: Name, STATE: State, TIME: CrawlElapsedTime}"
{
"NAME": "grok-accesslog-crawler",
"STATE": "READY",
"TIME": 0
}
こんな感じですかね。 READYは実行準備OK、つまり動いていない状態です。 一応クローラ実行も僅かながら課金されるので、実行時間も表示しておきます。
ではクローラを実行していきます。
# dbにある現在のテーブルを確認。 $ aws glue get-tables --database-name gensou-db --query "TableList[*].Name"
クローラの実行
# dbにある現在のテーブルを確認。(まだ何もないはず) DATABASE_NAME=access-log-db aws glue get-tables --database-name $DATABASE_NAME --query "TableList[*].Name" [] # クローラ実行 aws glue start-crawler --name grok-accesslog-crawler
実行直後にクローラの情報をみると、RUNNINGとなります。
aws glue get-crawler --name grok-accesslog-crawler --query "Crawler.{NAME: Name, STATE: State, TIME: CrawlElapsedTime}"
{
"NAME": "grok-accesslog-crawler",
"STATE": "RUNNING",
"TIME": 6793
}
しばらくするとSTOPPINGになります。
TIMEは51000ms...だと思います(単位違ってたら申し訳なし)
{
"NAME": "grok-accesslog-crawler",
"STATE": "STOPPING",
"TIME": 51000
}
READYに戻れば完了です!
{
"NAME": "grok-accesslog-crawler",
"STATE": "READY",
"TIME": 0
}
この時点でDatabaseの中身をみると、テーブルが作成されているはずです。
get-tablesでテーブルの存在を確認し、get-tableコマンドで詳しく中身を見てみます。
まずは新しく作成されたテーブル名を確認します。
DATABASE_NAME=access-log-db
aws glue get-tables --database-name $DATABASE_NAME --query "TableList[*].Name"
[
"log_resource_sample"
]
詳しくテーブルを見ていきます。 興味があるのはカラム定義と、自分がClassifierを定義したときのgrokパターンの比較です。
以下のようにqueryを使って出力を絞ると、定義したgrokパターンにしたがったテーブル定義となっていることを確認しやすくなります。
# 引っかかった名前で詳しく見る。
aws glue get-table --database-name $DATABASE_NAME --name log_resource_sample \
--query "Table.{MAPPING: StorageDescriptor.Columns, GROK: Parameters.grokPattern}"
{
"MAPPING": [
{
"Name": "client_ip",
"Type": "string"
},
{
"Name": "client_id",
"Type": "string"
},
{
"Name": "user_id",
"Type": "string"
},
{
"Name": "request_received_time",
"Type": "string"
},
{
"Name": "client_request",
"Type": "string"
},
{
"Name": "server_status",
"Type": "string"
},
{
"Name": " returned_obj_size",
"Type": "string"
}
],
"GROK": "^%{IPV4:client_ip} %{DATA:client_id} %{USERNAME:user_id} %{GREEDYDATA:request_received_time} %{QUOTEDSTRING:client_request} %{DATA:server_status} %{DATA: returned_obj_size}$"
}
ジョブの作成 & 実行
テーブルを作成することができたので、これでAthenaを使ってクエリを投げることもできます。
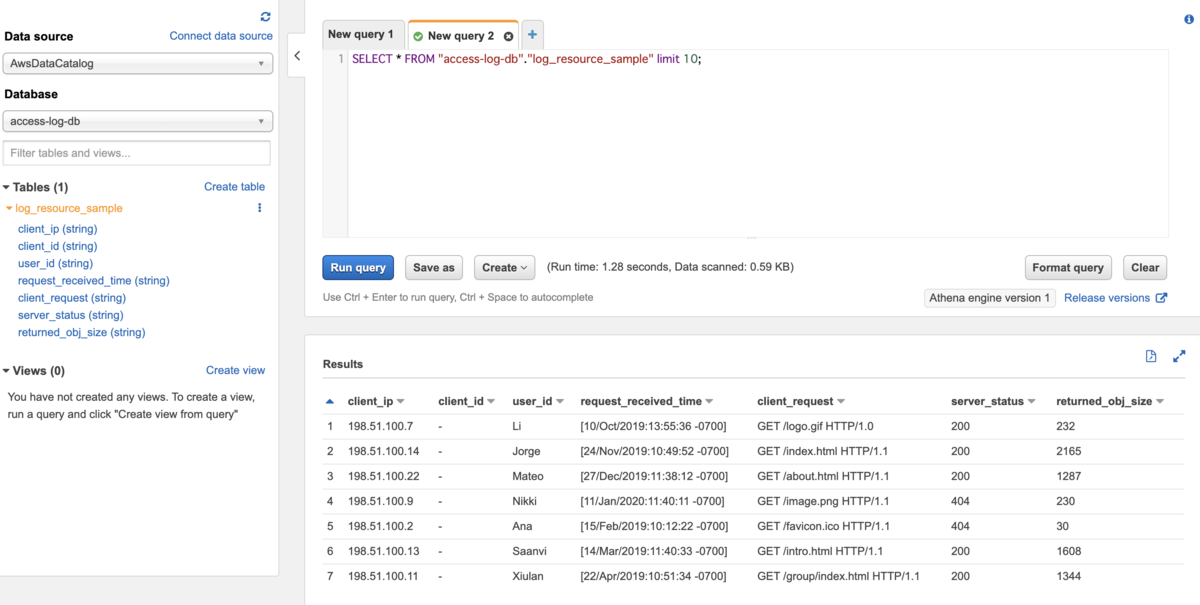
今回は「ログを解析に使う」ことを想定した手順となっています。ですので、統計処理やデータの変換を行うことを想定し、Glueのジョブを使った変換を行ってみます。
今回作るジョブはサンプルなので、「抽出したデータをjsonに変換する」というだけの処理を実行しようと思います。
ジョブスクリプトの作成
以下のスクリプトを作成します。以下の一文の、s3バケットに注意してください。自分のS3バケット名を指定しないとエラーとなってしまいます。
datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://your-bucket-name/log-output"}, format = "json", transformation_ctx = "datasink2")
以下のコードをjob-for-accesslog-convertion.pyというファイルをに記述して保存します(カレントディレクトリに置いてください)。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job ## @params: [JOB_NAME] args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "access-log-db", table_name = "log_resource_sample", transformation_ctx = "datasource0") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("client_ip", "string", "client_ip", "string"), ("client_id", "string", "client_id", "string"), ("user_id", "string", "user_id", "string"), ("request_received_time", "string", "request_received_time", "string"), ("client_request", "string", "client_request", "string"), ("server_status", "string", "server_status", "string"), (" returned_obj_size", "string", " returned_obj_size", "string")], transformation_ctx = "applymapping1") datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://your-bucket-name/log-output"}, format = "json", transformation_ctx = "datasink2") job.commit()
ファイルは、ジョブがアクセス可能なS3のバケットにアップロードしておきます。
S3_BUCKET_NAME='your_bucket_name'
S3_BUCKET_PREFIX='job-files'
aws s3 cp job-for-accesslog-convertion.py "s3://${S3_BUCKET_NAME}/${S3_BUCKET_PREFIX}/job-for-accesslog-convertion.py"
ジョブの作成と確認
ロールはクローラと同じ物を流用します。 parquetの吐き出し先S3への書き込み権限があることには注意しておきます。
JOB_NAME=grok-access-log-test-1217
JOB_ROLE=AWSGlueServiceRole-Tmp-Test
S3_BUCKET_NAME='your_bucket_name'
S3_BUCKET_PREFIX='job-files'
# 作成前に、ジョブがないことを確認。
aws glue list-jobs --tags Name=accesslog
# ジョブの作成
aws glue create-job --name $JOB_NAME \
--role $JOB_ROLE --glue-version "2.0" \
--number-of-workers 2 --worker-type "Standard" \
--command "Name=glueetl,ScriptLocation=s3://${S3_BUCKET_NAME}/${S3_BUCKET_PREFIX}/job-for-accesslog-convertion.py,PythonVersion=3" \
--tags Name=accesslog,Creation=cli
# 完了確認。
aws glue list-jobs --tags Name=accesslog
{
"JobNames": [
"grok-access-log-test-1217"
]
}
# ジョブの情報を見てみる。
aws glue get-job --job-name $JOB_NAME
# ジョブを削除する場合。
# aws glue delete-job --job-name grok-access-log-test-1217
https://docs.aws.amazon.com/glue/latest/dg/add-job.html
For AWS Glue version 2.0 jobs, you cannot instead specify a Maximum capacity. Instead, you should specify a Worker type and the Number of workers. For more information,....
--max-capacityというオプションはglue 2.0では使わず、Worker type and the Number of workersを指定すべきっぽいのでそのようにしました。
詳細はhelpを見れば詳しく書いてあります。
デフォルトの設定でジョブを作成すると、最小構成ではなくなるためジョブ実行コストが上がります。練習用にジョブを実行するときには、なるべく小さなリソースを割り当てると良いと思います。
リソースが足りなければ、ジョブの実行時にも指定して上書きできるため、ジョブ作成時には最小にしておけば問題ありません。
実際に最低限必要なオプションは、ジョブ名を決める--nameとジョブの種類とスクリプトの置き場所を決める--commandのみです。
ジョブの実行
aws glue start-job-run --job-name $JOB_NAME
S3の出力先を確認すればJSONファイルができているはずです。 この出力先S3ディレクトリをクロールして、新たにテーブルを作成すればAthenaでクエリをつかって中身をみることもできます。
今回はJSONファイルに変換しただけなのでETLスクリプトの恩恵は得られませんが、データの加工やS3以外のデータストアにデータを流すこともできるため、いろいろ試せそうです。またログファイル以外でも、grokパターンを使えばどんなパターンで書かれたファイルも解析して読み込むことができます。