【python】深いネストのdictから値を取り出す
前書き
例えば下のようなdictがあるとします。
d = {'category1': {'category2': {'sub_category1': {'sub_category2': {'numbers': [1, 2, 3]}}}}, 'category1b': {'category2b': {'sub_category1': {'sub_category2': {'numbers': [11, 12, 13]}}}}}
このdictから値を取り出すには、keyを辿らなければなりません。
>>> d['category1']['category2']['sub_category1']['sub_category2']['numbers'] [1, 2, 3]
これはかなり面倒ですし、可読性も低いです。 また、途中のkeyがどれかひとつでも存在しなければ、例外が発生します。
本来ならネストが深くならないようデータ構造を見直したり、dictではなくclassを使うなどの対策が適切だと思います。
しかし、既存のjsonを読み込んでdictに変換した...など、実装側ではどうにもならないことがあると思います。そのような場合に、深いネストのdictから値を取り出す方法をまとめました。
環境
| バージョン | |
|---|---|
| MacOS Big Sur | 11.1 |
| Python3 | 3.9.0 |
| python-box | 5.3.0 |
| jmespath | 0.10.0 |
参考リンク
1.単純なdictで頑張る
具体例
単純なdictで素直に書いた場合はどうなるか考えてみます。
d = {'category1': {'category2': {'sub_category1': {'sub_category2': {'numbers': [1, 2, 3]}}}}, 'category1b': {'category2b': {'sub_category1': {'sub_category2': {'numbers': [11, 12, 13]}}}}}
再掲になりますが、単純にkeyを辿るには、カッコを繋いで以下のように書きます。
>>> d['category1']['category2']['sub_category1']['sub_category2']['numbers'] [1, 2, 3]
ただし、途中のkeyが存在しなければ例外発生することに注意しなければなりません。
>>> d['category1']['category2']['NOT_EXISTING_KEY']['sub_category2']['numbers']
Traceback (most recent call last): .... KeyError: 'NOT_EXISTING_KEY'
これを回避する方法は一応あって、get(, {})を使って値を取り出すことです。
keyが存在しなければ、getの第二引数で指定した空のdict{}が渡され、それ以降は空振りし続けるという方法です。
>>> d.get('category1', {}).get('category2', {}).get('NOT_EXISTING_KEY', {}).get('sub_category2', {}).get('numbers', {}) {}
またはKeyError例外を拾うのもpythonっぽい書き方かなと思います。 こちらの方が意味は伝わりやすいですし、見た目もスッキリしているかなと思います。値が存在していなかった場合に渡す値もはっきりしています。
try: val = d['category1']['category2']['NOT_EXISTING_KEY']['sub_category2']['numbers'] except KeyError: val = 'NotFound' print(val) # OUT: NotFound
メリット
デメリット
[]を連ねる書き方が非常に書きづらく、可読性も低い。- 再利用が難しい。
- あるパスからあるパスまで...という部品を組み合わせて使うには、dictから順番に取り出す必要がある。
- パスを変数に入れておくことができない。
(再利用の例)以下のように、大カテゴリだけ変更して、それ以降のサブカテゴリは同じkeyでアクセスしたい時。 サブカテゴリ以降のパスは2回同じ内容をコピペして使うしかない。
>>> temp = d['category1a']['category2a'] # 大カテゴリ >>> temp['sub_category1']['sub_category2']['numbers'] [1, 2, 3] >>> temp2 = d['category1b']['category2b'] # CHANGED >>> temp2['sub_category1']['sub_category2']['numbers'] [5, 22, 31]
2. Box
具体例
割と有名で、2021現在もリリースされているライブラリです。
pipインストール後、以下のようにドットつなぎでkeyを指定できるdictのサブクラスを使うことができます。
>>> from box import Box >>> mybox = Box(d) >>> mybox.category1.category2.sub_category1.sub_category2.numbers <BoxList: [1, 2, 3]>
dictの[]つなぎと比べ、Boxのドットつなぎは見た目以上に書きやすいです。
なぜなら、IDEやvimプラグインを入れていれば、予測変換でkeyが表示されるからです。
ネストが深い場合に限らないのですが、基本的にdictが苦しくなってきたら、dataclassなど別のオブジェクトにする方がデータを追いやすいと、職場の先輩に教えていただきました。
存在しないキーへのアクセスは、専用のexceptionがraiseされます。それを利用してハンドルできます。(もっといい方法を後述します。)
>>> import box >>> try: ... mybox.category1.category2.NOT_EXISTING_KEY.sub_category2.numbers ... except box.exceptions.BoxKeyError: ... 'NotFound' ... ... 'NotFound'
個人的には、このBoxライブラリを使うことでネストされたdictの問題をほぼ全て解決できると思います。
「Box」のググラビリティがあまりに低いこと以外に、大きなデメリットはないと思います。
存在しないKey問題はdefault_boxでカスタムできる。
ドキュメントはこの辺です。
https://github.com/cdgriffith/Box/wiki/Types-of-Boxes
default_box引数をTrueにしてboxを作成します。そうすると、Keyが存在しない場合には空のBoxオブジェクトを返すようになります。
>>> mybox = Box(d, default_box=True)
>>> mybox.category1.category2.NOT_EXISTING_KEY.sub_category2.numbers
<Box: {}>
空のBoxオブジェクトはboolでFalse判定なので、値が取得できなかった場合の分岐も書きやすいです。
先述のBoxKeyErrorを使うより、こちらの方がスッキリ書けるケースも多いと思います。
キーつなぎ(パス)の再利用はbox_dotsで対処できる。
category1.category2とか、sub_category1.sub_category2.numbersなどの一連のキーの連なりを再利用したい場合、通常のdictの[]やBoxデフォルトのドットつなぎだと、基本的にコピペになります。
Boxには、キーの連なりを文字列で扱えるようにするオプションが用意されています。
>>> mybox = Box(d, box_dots=True) >>> mybox['category1.category2.sub_category1.sub_category2.numbers'] <BoxList: [1, 2, 3]>
これで通常dictの項目で述べた再利用問題は解決します。変数にパスを入れておいて、使うときに文字列連結すれば良いです。
d = {'category1': {'category2': {'sub_category1': {'sub_category2': {'numbers': [1, 2, 3]}}}}, 'category1b': {'category2b': {'sub_category1': {'sub_category2': {'numbers': [11, 12, 13]}}}}}
mybox = Box(d, box_dots=True) subcategory = 'sub_category1.sub_category2.numbers' mybox['category1.category2.' + subcategory] # OUT: <BoxList: [1, 2, 3]> mybox['category1b.category2b.' + subcategory] # OUT: <BoxList: [11, 12, 13]>
参考: Boxに類似したライブラリ
(AttrDictとbenedictは会社の同僚から教えていただきました。)
Boxと同じく、ドットアクセスを可能にしたdictのサブクラスを実装したライブラリは複数あります。
ただ、以下の観点から見ると、Boxが最も優れていると思います(個人的感想).
- Documentがしっかりしているか。
- 頻繁にリリースされているか。
- 深いネストに対応する機能が十分か。
3. jmespath
具体例
個人的におすすめなのがjmespathです。
これはdict側を改良したBoxとは異なり、普通のdictから値を取り出す便利な関数jmespath.searchを使うことでネスト問題を楽に解決することができます。
まず、ドットつなぎのアクセスは以下のように実行できます。 keyをつなげたパスは文字列です。そのため、先程のBoxで触れた例と同じく、パスの再利用は容易です。
>>> import jmespath >>> jmespath.search('category1.category2.sub_category1.sub_category2.numbers', d) [1, 2, 3]
存在しないkeyが入っていると、デフォルトでNoneが返ります。
>>> jmespath.search('category1.category2.NOT_EXISTING_KEY.sub_category2.numbers', d) is None True
Boxと同じく、性能的には十分です。Boxと比較すると以下のようなメリット/デメリットがあるかな?と思います。
メリット
- jmespathの記法を理解していれば、かなり柔軟なデータ操作が可能。(結合やソート、where句のような検索も可.)
- listなどが入ってきても柔軟に対処可能。
- pythonコード以外にも、terminalで利用するコマンドとしてパスを再利用できる。
デメリット
- Pythonっぽくなく、初見の人にとっては可読性が低い。
- とくにクエリはなんでもできてしまうため、複雑にしてしまいがち。
- IDEやvimプラグインを使っていても、ドットつなぎの予測変換ができない
- あくまで単なる文字列のクエリを書くことになる。
まとめ
個人的にはjmespathが好きです。個人で何かを作るときは、jmespathを使うと思います。
ただ、複数人が関わるプロジェクトを新しく始めるならBoxを使う方がメンテしやすいかな?と思います。初見でも直感的に使いやすいですし、複雑なクエリが生まれることもないため保守性に優れていると思います。
pythonでJSON Linesを作る方法
前書き
Json Linesというのは以下のような形式です。
{"name":"reimu","score":1}
{"name":"marisa","score":1}
JSON Linesに解説されていますが
そんなファイルです。 pysparkのデータ読み込みや、Elasticsearchのbulkでのデータ投入などで使ったりします。
このファイルをPythonを使って作成する方法を示しました。
参考リンク
- JSON Lines
- JSON Linesファイルの定義です。
- json — JSON encoder and decoder — Python 3.9.2 documentation
- pandas.DataFrame.to_json — pandas 1.2.3 documentation
- pandasのto_jsonメソッドの解説リンク。
環境
| バージョン | |
|---|---|
| MacOS Big Sur | 11.1 |
| Python3 | 3.9.1 |
| pandas | 1.1.4 |
Pythonのみを使う方法
以下のようなデータを用意します。
data_set = [
{'year': '2021', 'month': '01', 'day': '01', 'lang': 'Python', 'note': 'ぱいそん'},
{'year': '2021', 'month': '01', 'day': '01', 'lang': 'Ruby', 'note': 'るびぃ'},
{'year': '2021', 'month': '01', 'day': '01', 'lang': 'C++', 'note': 'しーぷらぷら'}
]
以下のように、リストの中身のオブジェクトを1行ずつ書き出します。
import json with open('test.jsonl', mode='w', encoding='utf-8') as fout: for obj in data_set: json.dump(obj, fout, ensure_ascii=False) fout.write('\n')
上述の、JSON Linesのルールを守るために以下の設定を行っています。
- utf-8エンコーディングを確約するために、open関数でencodingを指定する。
- 1行が一つのjsonとなるように、for文を使いながら毎行、json.dumpを行っています。
- 各行を
\nで区切っています。最終行の後にも付加されますが、それはどちらでもOKだとJSON Linesに明記されていました。 - 拡張子は
jsonlにしています。
Pandasを使う方法
こちらの方が圧倒的に簡単です。
以下のようなデータを用意します(上の例と同じ)。
data_set = [
{'year': '2021', 'month': '01', 'day': '01', 'lang': 'Python', 'note': 'ぱいそん'},
{'year': '2021', 'month': '01', 'day': '01', 'lang': 'Ruby', 'note': 'るびぃ'},
{'year': '2021', 'month': '01', 'day': '01', 'lang': 'C++', 'note': 'しーぷらぷら'}
]
以下のように、DataFrameを作ります。
import pandas as pd df = pd.DataFrame(data_set) df ## year month day lang note ## 0 2021 01 01 Python ぱいそん ## 1 2021 01 01 Ruby るびぃ ## 2 2021 01 01 C++ しーぷらぷら
書き出します。
df.to_json('test_pandas.jsonl', force_ascii=False, lines=True, orient='records')
force_asciiについては上述の通りです。
lines=Trueとorient=recordsパラメータによって、jsonlの形式になります。このことは公式ドキュメント公式ドキュメントのlinesの部分に記述されています。
linesbool, default False If ‘orient’ is ‘records’ write out line delimited json format. Will throw ValueError if incorrect ‘orient’ since others are not list like.
lines=Trueがjsonを1行ずつ出力するjsonlフォーマットのオプションであり、このオプションを正しく動かすために、DataFrameのrowを行として扱うorient=recoresの設定が必要..というイメージだと思います。
出力したjsonlファイルのlint(壊れてないかチェック)
json.toolがコマンドラインインターフェイスを提供しています。利用しているPythonが3.8以上でしたら、jsonだけでなく、jsonlもlintできるオプション--json-linesが提供されています!
$ python3 -m json.tool --json-lines test.jsonl > /dev/null
jsonlの形式が壊れていたら教えてくれます。
/dev/nullは標準出力を捨てています。jsonlファイルの中身が表示されてしまうため、大きなファイルだと扱いづらいので指定しています。
(jsonの壊れている部分は標準エラーで出力されます)
結論
Pandasを利用できる環境ならPandasを使えば良いと思います。 そうでないならPythonのjsonモジュールで頑張って書き出しましょう。
まとめ
もし、もっと簡単な方法などあればご教授いただけると嬉しいです! 間違いなどへのご指摘もいただけると幸いです。
【Python】f-stringとフォーマットの仕組みを特殊メソッド__format__から理解する。
前書き
先日、同僚の@JunyaFff、@takapdayon(それぞれtwitterアカウント)とPythonのfstringについての勉強会をしていた時の知見と、追加で調べたことを合わせてまとめました。
f-stringは知っているけど、パターンを覚えているだけで仕組みやFormat specificationsはよくわからない、という人向けの内容です。
参考リンク
- PEP 498 -- Literal String Interpolation | Python.org
- f-stringのPEPです。
- PEP 3101 -- Advanced String Formatting | Python.org
%を文字列フォーマットに使っていた時代に、format関数を提案しているPEPです。- f-stringも、仕組みはformat関数を使っているだけなので参考になります。
- string — Common string operations — Python 3.9.2 documentation
- formatのドキュメントです。
help('FORMATTING')とすることで、python-shellから閲覧できます。
- 2. 字句解析 — Python 3.9.2 ドキュメント
- f-stringのドキュメントです。
環境
| バージョン | |
|---|---|
| MacOS Big Sur | 11.1 |
| Python3 | 3.9.1 |
f-stringの例と用語
f-stringはfを先頭につけた文字列リテラルです。文字列リテラル中では、波括弧{}によって、変数を置換することができます。
波括弧の部分は、置換フィールド(replacement field) と呼ばれているようです(参考リンク参照)。
>>> a = '1' >>> print(f'-{a}-') -1-
replacement field中で、!r、!sまたは!aを変数の後ろに指定することで後述の__format__()をオーバーライドして変数の値を変換します。
この!から始まる型変換を、公式ドキュメントではconversion フィールド(conversion) と呼んでいるようです。
>>> a = '1' >>> print(f'-{a!r}-') -'1'- # これと同じ。 >>> print(f'-{repr(a)}-') -'1'-
またreplacement field中では:から始まるさまざまな記号を指定できます。下の例では「値を右寄せにしてスペース5つとなるよう0で埋める」という意味になります。
この:による書式の指定は、書式指定、書式指定文字列(format_spec、Format specifications) などと呼ばれているようです。
>>> print(f'-{a:0>5}-') -00001-
f-stringで使う用語のまとめ
- 置換フィールド(replacement field):
{}の中身。 - conversion フィールド(conversion):
!sなど。 - 書式指定、書式指定文字列(format_spec、Format specifications):
:0>5など。
最強コマンド: help('FORMATTING')
string --- 一般的な文字列操作 — Python 3.9.2 ドキュメント
こちらのドキュメントは、pythonのシェルに入り、help('FORMATTING')とすればいつでも見ることができます。
conversionやformat specificationsに指定できる値は、こちらからいつでも確認できて便利です。
特に、最後の方には例文がたくさん乗っていてそのまま使えます。
フォーマットの仕組みを考える
replacement fieldのフォーマットの仕組みを、例を挙げて考えてみます。
conversionフィールドは特殊メソッド__str__などを呼ぶ.
以下のクラスを定義します。
class MyClass: def __str__(self): return ('__str__') def __repr__(self): return ('__repr__')
このクラスをインスタンス化し、str(), repr()関数の引数にインスタンスを渡すと、特殊メソッド__str__(), __repr__()が呼ばれていることがわかります。
myclass = MyClass() str(myclass) # '__str__' repr(myclass) # '__repr__'
conversionの!s, !rでも、全く同じことをやっています!
print(f'-{myclass!s}-') # -__str__- print(f'-{myclass!r}-') # -__repr__-
f-stringの置換フィールド中では、__format__()メソッドが呼ばれる。
先程のクラスのインスタンスですが、conversionを指定せずに呼ぶと以下のように、__str__()が呼ばれます この挙動がなぜ起こるのか、正確に考えてみます。
print(f'-{myclass}-') # -__str__-
まず、新しく__format__メソッドを導入したクラスを定義します。
class MyClassModFormatting: def __str__(self): return ('__str__') def __repr__(self): return ('__repr__') def __format__(self, format_spec): return ('__format__')
先ほどと同様にインスタンス化し、conversionをやってみます。
すると、f-stingの置換フィールドにインスタンスをおくと、__format__が呼ばれていることがわかります。
>>> myclass_mod = MyClassModFormatting() >>> print(f'-{myclass_mod}-') -__format__-
実は、f-sting中の置換フィールドでは、変数に対して組み込み関数format()を呼んでいるだけなのです。
そして組み込み関数format()は、対象のクラスの__format__()に全ての処理を丸投げする関数です。
format関数の定義は以下のようなものです。 PEP 3101 に定義が乗っています
def format(value, format_spec): return value.__format__(format_spec)
書式指定文字列(format_spec)の解釈は対象のクラス次第である。
format()関数、__fomrat__()メソッドは第二引数に書式指定文字列(format_spec)をとります。f-stringでは:から始まる記号です。
この書式指定文字列の解釈はクラスの__format__()の定義に完全に依存しています。換言すると、同じformat_specを指定しても、解釈は対象のクラスによって異なります。
以下のクラスは、与えられたformat_specをアットマークつきで返します。
class MyClassPritingSpec: def __format__(self, format_spec): return '__format__' + '@' + str(format_spec)
以下のようになります。f-stringのformat_spec(:以降の部分)をパースするのは、フォーマットされるクラスに定義された特殊メソッド__fomrat__()だということがわかります。
spec_printer = MyClassPritingSpec() print(f'-{spec_printer:hoeeee}-') # -__format__@hoeeee-
datetime.datetimeオブジェクトは特殊な書式指定文字列を持つ
datetime.datetimeはstrftimeによってフォーマットされますが、これもformattingの仕組みを使っています。
以下の結果は全く同じです。dateimeクラスに定義された__format__()が、日付型専用の書式指定文字列をパースできるように定義されているのです。
>>> import datetime >>> d = datetime.datetime(year=2000, month=3, day=3) >>> d.strftime('%Y-%m') '2000-03' >>> f'{d:%Y-%m}' '2000-03'
デフォルトの__format__()はobjectに定義されている
ここで最初の疑問に戻ります。__format__()を定義していないクラスMyClassのインスタンスは、f-stringにかけて出力すると以下のように__str__()が呼ばれるのでした。
print(f'-{myclass}-') # -__str__-
これは、自作クラスが継承しているobjectに定義された__format__()メソッドの挙動です。
PEP 3101 PEPとしてはここに記載されています。 引用すると、以下のようになっています。
class object: def __format__(self, format_spec): return format(str(self), format_spec)
引用終わり。
オブジェクトに対して、str()を呼んでからformatを呼んでいることがわかります。
ですので、先の例では-__str__-と出力されていたのでした。
再確認: conversion(!r)は__format__をオーバーライドする
最初の説明で、!rや!sなどのconversionは「formatをオーバーライドする」と述べました。その実例をみていきます。
先程のMyClassModFormattingを再び使います。インスタンス化したあと、conversionを行います。
print(f'-{myclass_mod!s}-') # -__str__- print(f'-{myclass_mod!r}-') # -__repr__-
結果、このクラスは自分で定義した__format__()が呼ばれていないということがわかります。__format__()の処理が、__str__()や__repr__()で上書きされたのです。
ただし、!sや!rで変換した後のstringに対してはformatが呼ばれています。 書式指定文字列を渡さない場合、strはそのまま出力されるのでわかりにくいため、以下のようにしてみます。
>>> print(f'-{myclass_mod!s:0>30}-') # -00000000000000000000000__str__-
このように、文字列に変換されたあとは「 str型に定義されている__format__ 」が呼ばれていました。
まとめ
f-stringはpython3.6から導入された便利な構文です。ただし、その処理の実体はPEP3101に記載があるformatの仕組みがそのまま使われています。(pythonのバージョンとしては3.0〜。これ以前は%によるフォーマットと、テンプレートシステムだけが存在していたようです。)
formatの仕組みは一見複雑に見えますが、基本的には3つの特殊メソッド__str__, __repr__, __format__で成り立っています。また、intかstrのformatに使う書式指定文字列を覚えていればよく、その例文はhelp('FORMATTING')でいつでもサッと確認できます。
科学計算の数値表現はもちろん、Web開発での文字列の組み立て、ログへの出力(!rを用いて型情報付きで出力するのが便利!)などなど、あらゆる場面で利用できます。仕組みを理解して上手に使っていきたいなと思います。
tmux + zsh環境でEmacsキーバインド [ ctrl + a ] や [ctrl + e]が効かない時の対処方法
問題
タイトルの通りです。
会社のMacをBig Surにアップグレードしたところ、なぜかターミナルでの作業でctrl+a(行の先頭に移動)や、ctrl+e(行末に移動)ができなくなってしまいました。これらのキーを押すと^Aや^Eが表示されてしまいます...
bashを使うとこの現象は起こりませんでした。どうやら、tmux + zshの時のみemacsキーバインドが解除されているようでした。

修正
tmuxのセッション中でkeybindを確認すると、Aキーはそのまま入力されるようになっているようでした(self-insertと書かれていた)。
# tmux中で実行 % bindkey | grep A "^A"-"^C" self-insert
一方、tmuxの外で同じようにkeybindを確認すると、行の先頭に移動するようになっていました。
% bindkey | grep A "^A" beginning-of-line
調べてみると、これはctrl+eなども含め、以下の設定で「emacs風のkeybind」として一括で設定できるらしいので~/.zshrcに以下のように追記しました。
また注意点として、この記述は.zshrc内の、他のbindkeyコマンドより上に記述する必要があります!
そうしないと、上流で設定したbindkeyコマンドはbindkey -eで上書きされて無効になってしまうようです。
.zshrc
bindkey -e # emacsのキーバインド
あとは設定を読み込みます。
% source ~/.zshrc
無事、tmuxのセッション内部でもctrl+aで行頭に戻ることができるようになりました!

環境
| バージョン | |
|---|---|
| MacOS Big Sur | 11.1 |
| tmux | 3.1c |
| zsh | 5.8 (x86_64-apple-darwin20.0) |
参考リンク
本記事を書くにあたり、以下のリンクを参考にさせていただきました。
よく実行するコマンドにキーバインドを割り当てると捗る話 - Qiita
command line - CTRL-a and CTRL-e map incorrectly in tmux - Ask Ubuntu
【AWS CloudShell】tmuxを立ち上げた状態でタイムアウトするとアクセスできなくなる?
原因はわからないし解決もしていないのですが、ググっても同じ状態になっている人が見つからなかったのでインターネットの海に状況を共有するという意味で記事を書いておきます(後で消すか、原因がわかったら書き直します)

以上のように、
Unable to start the environment. To retry, refresh the browser or restart by selecting Actions, Restart AWS CloudShell. System error: The XXXXXX is exceeding the monthly hours limit.
と表示され、リロードしても再起動しても同じメッセージが表示されて使えない状態になってしまいました。
まだ1時間程度しか使っておらず、最後にやったことといえばtmuxのsessionを立ち上げ、おやつを食べている間にタイムアウトになった...くらいです。
CloudShellは課金されないサービスで、特に困ってはいないので一旦様子見しようと思います。
2021/01/28追記
いつの間にか復活していました。AWS側の障害だったのでしょうか?
Pythonで個人用CLIツールを作成する
前書き
Pythonを使って、個人用CLIツールを作成するときの手順と参考になるリソースのまとめです。
最終的に、こんなイメージで使えるようにします。(例: noteというコマンドを作成)
# 仮想環境に入る % source env/bin/activate # 自作ツールのpip install (env) % pip install --editable . # 自作ツールを使う (env) % note "abc def efg"
GitHub
サンプルコードをgithubにアップロードしました。
GitHub - Kyutatsu-sandbox/python-cli-for-blog: sample code for blog post.
参考リンク
setup.pyを書いてパッケージ化する方法
How To Package Your Python Code — Python Packaging Tutorial
pythonのsetup.pyについてまとめる - Qiita
コマンドの引数を扱う標準ライブラリArgparse公式チュートリアル
Argparse チュートリアル — Python 3.9.1 ドキュメント
ターミナルで文字に色をつけるためのPythonライブラリ
環境
| バージョン | |
|---|---|
| MacOS Catalina | 10.15.6 |
| Python3 | 3.9.0 |
※ 古い方のMacを使ったのでCatalinaに戻ってます。誤植ではありません。
setup.pyを作成する
まずは仮想環境に入ります。
% python3.9 -m venv env % source env/bin/activate
メインとなるpythonファイル(cli.py)とセットアップ用のファイルsetup.pyを作成します。
(env) % touch {cli,setup}.py
# このような構成になっていればOK
(env) % tree -L 1
.
├── cli.py
├── env
└── setup.py
まずcli.pyには、処理の入り口となる関数を定義します。コマンドを叩いたときに呼ばれる関数です。
- cli.py
from termcolor import colored, cprint def main(): print('STDOUT') return 'RETURN' def color(): cprint('STDOUT', 'green') text = colored('RETURN', 'red') return text
二つ関数を定義しました。color関数では、参考リンクに記述したライブラリtermcolorを利用しています。
ANSIカラー文字列を付加するwrapperです。ターミナル上に出力される文字列に色をつけることができます。
次にsetup.pyを書きます。
from setuptools import setup setup( name='mycli-package', version='1.0.0', install_requires=['termcolor>=1.1.0'], entry_points={ "console_scripts": ['mycli = cli:main', 'mycli_color = cli:color'] } )
とりあえず自分で作成したツールを使う上では上記の設定だけ分かっていれば事足りると思います。 詳しい説明は、参考リンクとして挙げた記事などを参照してください。
少し補足します。
install_requires
依存パッケージです。ここに書いておいたパッケージが、自作ツールをpipで入れるときに一緒にインストールされます。
package==1.0.0 (バージョン1.0.0を必ずいれる) のようなバージョン指定もできますし、単にpackageと言うふうに名称を書くだけでもOKです。
上記の例では1.1.0以上、としています。
entry_points
実際に、「コマンド(上例だとmycli, mycli_color)」と「実行される関数(上例だとmain, color)」をマッピングします。
console_scriptsというキーは決まっていて、CLIツールとして利用するコマンドをこのエントリーポイントへ書くことになっています(console_scripts Entry Point)。
pipでインストールする
ではコマンドを使ってみます。
まずは別の仮想環境を作成し、そちらに入ります。 (依存インストールなどがうまくいくことを確認するために行う手順です。ツール作成に必須ではありません)
% python3.9 -m venv another_env % source another_env/bin/activate # 出力なし。 (another_env) % pip freeze
先ほど作成したsetup.pyが存在するディレクトリへのパスを指定し、以下のようにしてインストールを行います。
(--editableについては後述)
# setup.pyがあるディレクトリ
(another_env) % pip install --editable /Users/yourname/XXXX/python-cli-tool-template
pip freezeで確認します。
依存ライブラリとして設定したtermcolorも一緒にインストールされていることがわかります。
(another_env) % pip freeze # Editable Git install with no remote (mycli-package==1.0.0) -e /Users/yourname/XXXX/python-cli-tool-template termcolor==1.1.0
ではコマンドを使ってみましょう!
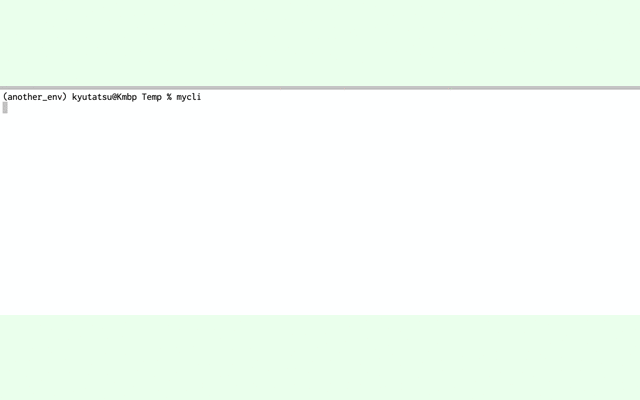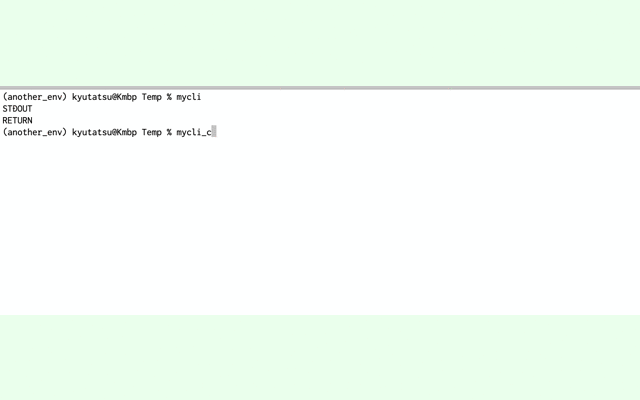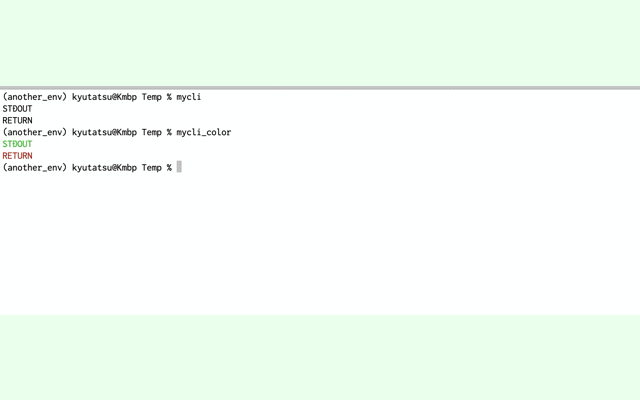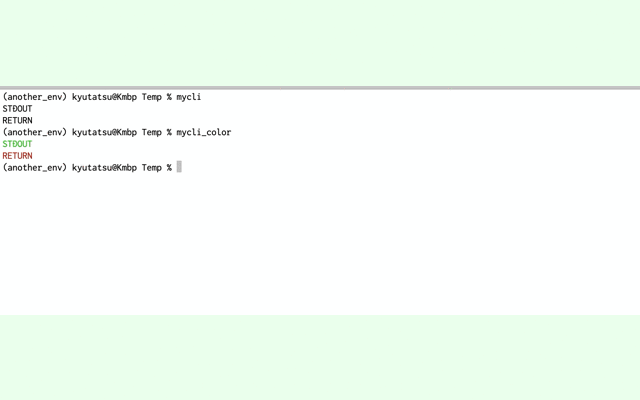
mycliコマンドで黒色の文字、mycli_colorで色付き文字がプリントされていることがわかります。
retrunした値は標準エラーに出力される
結果を見ると気が付くと思いますが、printで出力した文字だけでなく、returnした値も表示されています。
returnした値は標準エラー扱いです。
標準出力(1)を/dev/nullに捨てる、もしくは標準エラー(2)を捨てると以下のようになります。
(another_env) kyutatsu@Kmbp Temp % mycli 1> /dev/null RETURN (another_env) kyutatsu@Kmbp Temp % mycli 2> /dev/null STDOUT
普通に使っているとどちらも表示されてしまいますが、以上のような挙動になっているので気をつけます。(詳しい理由と仕組みを知っている方がいれば教えていただけると幸いです)
--editableオプションをつけるとコードへの変更が即反映される
先ほどツールを入れるときに指定した--editableオプションですが、これは「develop mode」でのインストールになります。
ではdevelop modeとはなんぞやと言うことになりますが、順番に辿っていこうと思います。
実際の挙動
まずは挙動をみてみます。 先ほどインストールした自作ツールに変更を加えます。
- cli.py
def main(): print('@@@@@@@@@@@@@STDOUT@@@@@@@@@@') return 'RETURN'
保存してファイルを閉じ、mycliコマンドを打ってみます。
(another_env) % mycli @@@@@@@@@@@@@STDOUT@@@@@@@@@@ RETURN
変更が反映されています。
では、--editableをつけなかった場合はどうなるのでしょうか。
まずcli.pyを元に戻します。
def main(): print('STDOUT') return 'RETURN'
別の環境でインストールを行います。
# 別の環境 % python -m venv not_editable % source not_editable/bin/activate # 何もないことを確認 (not_editable) % pip freeze
MuduleNotFoundErrorを回避する
注意 Editableモードならこのままインストールすれば良いのですが、通常インストールではpackageやmoduleの場所を指定する必要があります。
今回は、setup.pyと同じディレクトリにモジュール(cli.py)を置いているので、以下のように追記します。このように書かないと、moduleを見つけることができずにエラーとなります。
- setup.py
setup( # .......(省略).......... py_modules = ['cli'], # .......(省略)..........
ではインストールしていきます。
% pip install /User/yourname/XXXX/python-cli-tool-template
ここでfreezeしてみると、先ほどとは出力が違っていることがわかります! 自作ツールについていたはずのコメントなどや、editableモードであることを示す記述がなくなり、通常のライブラリと同じようにprintされています。
% pip freeze mycli-package==1.0.0 termcolor==1.1.0
今ここで、cli.pyを編集してみます。
def main(): print('--------------STDOUT^---------------') return 'RETURN'
次にmycliコマンドを実行します。 先ほどと異なり、編集した内容が反映されません
反映されるには、パッケージを通常と同じように更新する必要があります
まずsetup.pyのバージョンもあげておきましょう。
- setup.py
from setuptools import setup setup( name='python-cli-tool-template', version='1.1.0', # バージョンあっぷ! # ....(省略)......... )
インストールします。
(not_editable)% pip install --upgrade ~/MyProjects/GitHubForBlog/python-cli-tool-template # 確認すると、バージョンが上がっているはず。 (not_editable) % pip freeze python-cli-tool-template==1.1.0
挙動も更新されました!
(not_editable) % mycli --------------STDOUT^--------------- RETURN
editableモードの説明をドキュメントからたどる
まずはpipのヘルプをみてみます。
% pip install --help | grep -A 2 editable
-e, --editable <path/url> Install a project in editable mode (i.e.
setuptools "develop mode") from a local project
path or a VCS url.
(余談: grepの -A 2は該当する行+後ろ2行も表示、と言う意味です)
「editable mode」は setuptoolsの「develop mode」を意味していることがわかります。
そこでsetuptools のドキュメントから該当箇所を探します。
Building and Distributing Packages with Setuptools — setuptools 51.1.1 documentation
Deploy your project in “development mode”, such that it’s available on sys.path, yet can still be edited directly from its source checkout.
ソースを直接変更できると言うことが書かれています。
さらに詳しい箇所がありました。 “Development Mode” — setuptools 51.1.1 documentation
It works very similarly to setup.py install, except that it doesn’t actually install anything. Instead, it creates a special .egg-link file in the deployment directory, that links to your project’s source code.
つまりeditableモードでinstallをした場合にはinstall先の仮想環境には何もインストールされず、直接ソースコードとコマンドがマップされるみたいですね。
Argparseでコマンドに引数を渡す
公式チュートリアルがあるので紹介程度に留めますが、作成したコマンドの引数を処理するには標準ライブラリArgparseが利用できます。
Argparse チュートリアル — Python 3.9.1 ドキュメント
- 自動でヘルプ(
-h)作成 - 同時に使えない引数の設定や、可変長引数などの設定
など、sys.argsを直接パースしていては苦しい処理が楽にかけます。
上記チュートリアルを完了したら、以下のadd_argument関数のドキュメント部分を読めば大抵のことができると思います。
argparse --- コマンドラインオプション、引数、サブコマンドのパーサー — Python 3.9.1 ドキュメント
また、CLIツールを作成するフレームワークも存在します。本格的なCLIツールを作成したければそちらを使った方がいいかもしれません。 (自分は使ったことがないので、リンクの紹介のみです)
Pythonの組み込み関数zipに渡したイテレータはコピーされず、元のイテレータが消費される
前書き
タイトル通りの小ネタです。
この挙動を積極的に利用しているコードを散見するのですが、見るたびに混乱するので自分への戒めとしてまとめておきました。
参考リンク
Python公式zip()関数の説明
Built-in Functions — Python 3.9.1 documentation
環境
| バージョン | |
|---|---|
| MacOS Catalina | 10.15.6 |
| Python3 | 3.9.0 |
本題: 何が起こるのか?
タイトルの通り、「zipに渡したイテレータはコピーされず、元のイテレータが消費される」例を示します。
まずはイテレータを作成します。printすると、list_iterator objectがそれぞれ作成されたことを確認できます。
# イテレータの作成と確認 >>> str_it = iter(['a', 'b', 'c']) >>> int_it = iter([1, 2, 3]) >>> print(str_it, int_it) <list_iterator object at 0x114320910> <list_iterator object at 0x113e09d60>
これらのイテレータをzip関数に渡します。 zip関数自体も、イテレータを返します。nextを使って値を取り出してみると、zipに渡した二つのイテレータのそれぞれの最初の要素がタプルの形で取り出されていることがわかります。
>>> zipped = zip(str_it, int_it) >>> next(zipped) ('a', 1)
このタイミングで、zip()関数に渡したstr_itとint_itをnextしてみます。
すると、これらのイテレータを直接nextしたのはこれが初めてなのに、両方とも2番目の値が取得されました。
# 最初の要素 'a' ではなく、次の要素 'b' が返ってきた! >>> next(str_it) 'b' # 最初の要素 1 ではなく、次の要素 2 が返ってきた! >>> next(int_it) 2
このままもう一度zippedをnextしてみましょう。
予想通り、先ほどstr_itとint_itを一つ進めた影響が反映されているので、イテレータの最後の値が出力されます。
>>> next(zipped) ('c', 3)
zipにイテレータを渡した際の挙動を理解する
これまでにみてきた挙動は、単純に「渡したイテレータオブジェクトが、そのまま消費されている」だけなのですが、ドキュメントを見るとちょっと面白い事実がわかります。
Built-in Functions — Python 3.9.1 documentation
上記リンクから、zipの実装のイメージコード引用します(実際にはCで書かれているはずなので、あくまでイメージですが..)。
def zip(*iterables): # zip('ABCD', 'xy') --> Ax By sentinel = object() iterators = [iter(it) for it in iterables] while iterators: result = [] for it in iterators: elem = next(it, sentinel) if elem is sentinel: return result.append(elem) yield tuple(result)
今回注目したいのは以下の部分です。
iterators = [iter(it) for it in iterables]
可変長引数として渡されたiterablesについて、組み込みのiter関数を実行しています。
例えば、渡したiterablesがlistだった場合はこのタイミングでイテレータオブジェクトが作成されるだけです。ところが、イテレータが渡された場合に、iter関数は以下のように元のイテレータオブジェクトをそのまま返します。 (下のコード参照)
>>> it = iter([1,2,3]) # イテレータオブジェクトにiter()関数を使う。 >>> it_new = iter(it) # 全く同じオブジェクト!! >>> print(f"{id(it)} is {id(it_new)}") 4633907264 is 4633907264
以上の2点から、以下の仕組みがわかりました。