【Django】例文で理解するselect_relatedとprefetch_relatedパターン集
- 前書き
- 参考リンク
- 環境
- 事前準備: モデルの作成とデータ投入
- No.0 発行されたSQLを確認する
- No.1 select_relatedで親を取る
- No.2 select_relatedで親の親を取る
- No.3 prefetch_relatedで複数件の多を取る
- No.4 Prefetchオブジェクトで多をfilter
- No.5 prefetch_relatedで2つ先のリレーション: ManyToMany-ManyToMany
- No.6 prefetch_relatedで2つ先のリレーション: ForeignKey-ManyToMany
- No.7 prefetch_relatedで2つ先のリレーション: ForeignKey-ManyToMany + select_related
- No.8 Prefetchで2つ先のリレーションをorder_byする
- No.9 prefetch_relatedで2つ先のリレーション: ManyToMany-ForeignKey
- No.10 to_attrで複数の絞り込みをする
- No.11 1つ先、2つ先のリレーションをそれぞれ条件付きでPrefetch(ManyToMany-ManyToMany)
- No.12 親ベースで1件の子を取得する
前書き
去年末もDjangoを書いてました。
DjangoのORMは簡潔な記述でSQLの発行とPythonオブジェクトを橋渡ししてくれて便利です。
しかし何も考えずに使っているとSQLの発行数が増えてきて、パフォーマンスがどんどん下がってきます。 効率のよいSQLを発行してもらうためにselect_relatedとprefetch_relatedを使用します。
自分は毎回「このパターンどうするんだっけ...」と忘れてしまうので、パターン集を作成しました。
以下のような人向けです。
- モデルが複雑になってくると混乱して、クエリ削減実装の手が止まってしまう。
- select_related/prefetch_relatedの基本的な使用方法と目的は理解している。
- SQLを最低限理解している(INNER JOIN, OUTER JOIN, WHERE, IN あたりの基本構文)
サンプルは全てdjango shellで実行しており、データ作成コードも乗せているので、すぐに試すことができます。
参考リンク
本記事は公式ドキュメントの例を元に、補足を追加した内容です。
環境
| バージョン | |
|---|---|
| MacOS Ventura | 13.5.2 |
| Python3 | 3.11.4 |
| Django | 5.0.1 |
Djangoの環境を構築する方法は以下を参考にしてください。
事前準備: モデルの作成とデータ投入
以下のドキュメントで出されている例を少し改変しています。
QuerySet API リファレンス | Django ドキュメント | Django
ピザ、トッピング、レストランのモデルです。
- ピザとトッピングは多:多の関係。
- レストランはpizzasフィールドでピザと多:多の関係にあります。(提供するピザ全て)
- レストランはbest_pizzaフィールドでピザと多:1の関係にあります。(一番人気のピザ)
- この時、ピザが親です.
from django.db import models class Country(models.Model): name = models.CharField(max_length=256) def __str__(self): return self.name class Topping(models.Model): name = models.CharField(max_length=256) def __str__(self): return self.name class Pizza(models.Model): name = models.CharField(max_length=256) country = models.ForeignKey( Country, related_name='pizza', null=True, on_delete=models.CASCADE) toppings = models.ManyToManyField(Topping) def __str__(self): return self.name class Restaurant(models.Model): name = models.CharField(max_length=256) # 追加 pizzas = models.ManyToManyField(Pizza, related_name='restaurants') best_pizza = models.ForeignKey( Pizza, related_name='championed_by', on_delete=models.CASCADE) def __str__(self): return self.name
マイグレーションします。
(env) $ python manage.py makemigrations (env) $ python manage.py migrate
データ投入したいので、django shellに入ります。
(env) $ python manage.py shell
シェル内部で以下のコードを実行します。
from app.models import Topping, Pizza, Restaurant, Country i = Country.objects.create(name='イタリア') Topping.objects.create(name='トマト') Topping.objects.create(name='ピクルス') Topping.objects.create(name='ベーコン') Topping.objects.create(name='パイナップル') Topping.objects.create(name='チーズ') Topping.objects.create(name='焼き魚') pizza_A = Pizza.objects.create(name='ピザA') pizza_A.toppings.set(Topping.objects.filter(name__in=['トマト', 'ピクルス', 'ベーコン'])) pizza_A.country = i pizza_A.save() pizza_B = Pizza.objects.create(name='ピザB') pizza_B.toppings.set(Topping.objects.filter(name__in=['トマト', 'ピクルス', 'パイナップル', 'チーズ'])) pizza_C = Pizza.objects.create(name='ピザC') pizza_C.toppings.set(Topping.objects.filter(name__in=['トマト', '焼き魚'])) restaurant_1 = Restaurant.objects.create(name='レストラン1', best_pizza=pizza_A) restaurant_1.pizzas.set(Pizza.objects.filter(name__in=['ピザA', 'ピザB'])) restaurant_2 = Restaurant.objects.create(name='レストラン2', best_pizza=pizza_C) restaurant_2.pizzas.set(Pizza.objects.filter(name__in=['ピザA', 'ピザC']))
No.0 発行されたSQLを確認する
通常SQLの発行はdjango-debug-toolbarを導入したり、logから確認することが多いと思います。 今回はdjango shellだけで完結させるので、django.db.connection.queriesを確認します。 ここに発行されたSQLの履歴が入っています。
django shellへの入り方を再掲します。
(env) $ python manage.py shell
また、発行されたSQL部分のみを確認したいので、以下のヘルパー関数を定義しておきます。(django shellに貼り付ければOKです)
from django.db import reset_queries, connection def f(q): for qt in q: print(qt['sql']) # クエリ確認 f(connection.queries) # リセット reset_queries()
以降、全てdjango shell内部で実行しています。
No.1 select_relatedで親を取る
レストラン: 一番人気のピザは多:1の関係です。 レストラン(子)から検索すると、一番人気のピザ(親)は1つにさだまります。
素の状態だとレストランを取得するクエリに加え、取得されたレストランの数だけ一番人気のピザを取るクエリが発行されてしまいます。
>>> for restaurant in Restaurant.objects.all(): print(f'{restaurant.name}店の一番人気のピザは{restaurant.best_pizza.name}') レストラン1店の一番人気のピザはピザA レストラン2店の一番人気のピザはピザC
>>> f(connection.queries) SELECT "app_restaurant"."id", "app_restaurant"."name", "app_restaurant"."best_pizza_id" FROM "app_restaurant" SELECT "app_pizza"."id", "app_pizza"."name" FROM "app_pizza" WHERE "app_pizza"."id" = 1 LIMIT 21 SELECT "app_pizza"."id", "app_pizza"."name" FROM "app_pizza" WHERE "app_pizza"."id" = 3 LIMIT 21
このような場合、SQLでは親を結合して取得します。 DjangoのORMでは、select_relatedによって結合が可能です。
発行されたSQLを確認すると、確かにINNER JOINされており、クエリ発行数は1件となっています。やりました。
>>> reset_queries() # 初期化しておきます. >>> for restaurant in Restaurant.objects.select_related('best_pizza').all(): print(f'{restaurant.name}店の一番人気のピザは{restaurant.best_pizza.name}') レストラン1店の一番人気のピザはピザA レストラン2店の一番人気のピザはピザC
>>> f(connection.queries) SELECT "app_restaurant"."id", "app_restaurant"."name", "app_restaurant"."best_pizza_id", "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_restaurant" INNER JOIN "app_pizza" ON ("app_restaurant"."best_pizza_id" = "app_pizza"."id")
No.2 select_relatedで親の親を取る
ダブルアンダースコアによって、親の親の...と辿ることができます。 後半は、LEFT OUTER JOINとなっていることに注意してください。(CountryはピザAにだけ設定しています。)
for restaurant in Restaurant.objects.select_related('best_pizza__country').all(): print(f'{restaurant.name}店の一番人気のピザは{restaurant.best_pizza.name}({restaurant.best_pizza.country})') レストラン1店の一番人気のピザはピザA(イタリア) レストラン2店の一番人気のピザはピザC(None)
>>> f(connection.queries) SELECT "app_restaurant"."id", "app_restaurant"."name", "app_restaurant"."best_pizza_id", "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id", "app_country"."id", "app_country"."name" FROM "app_restaurant" INNER JOIN "app_pizza" ON ("app_restaurant"."best_pizza_id" = "app_pizza"."id") LEFT OUTER JOIN "app_country" ON ("app_pizza"."country_id" = "app_country"."id")
ところで、以下のようなコードを書く必要はありません。 親の親の親...と辿る時は、一番遠い親を指定すれば良いです。
ダブルアンダースコアで指定すれば、その途中のテーブルもきちんと結合されます。
# 冗長な例. best_pizzaの指定は不要. select_related('best_pizza', 'best_pizza__country')
No.3 prefetch_relatedで複数件の多を取る
よく解説されている基本の形です。
ピザとトッピングは多:多の関係です。ピザをベースにして取得します。
取得したそれぞれのピザの、トッピングも全て取得したい というケースを考えます。 以下のようにアクセスするとピザを取得するクエリ(1つめ)に加え、取得したピザの数だけ、そのピザに紐つくトッピングを取得するクエリが発行されてしまいます。
f(connection.queries) reset_queries() for pizza in Pizza.objects.all(): print(f'{pizza.name}', ','.join([t.name for t in pizza.toppings.all()])) ピザA トマト,ピクルス,ベーコン ピザB トマト,ピクルス,パイナップル,チーズ ピザC トマト,焼き魚
>>> f(connection.queries) SELECT "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" SELECT "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE "app_pizza_toppings"."pizza_id" = 1 SELECT "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE "app_pizza_toppings"."pizza_id" = 2 SELECT "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE "app_pizza_toppings"."pizza_id" = 3
このようなケースでは、SQLとやや異なる方法を取ります。
prefetch_relatedによってトッピングをあらかじめ別のクエリで取得し、Pythonコードによって結合します.
prefetch_relatedはキャッシュ機能(Python側の機能)だと意識すると、理解しやすいと自分は思います。
では実際にクエリを見てみます。
>>> reset_queries() >>> for pizza in Pizza.objects.prefetch_related('toppings').all(): print(f'{pizza.name}', ','.join([t.name for t in pizza.toppings.all()])) ピザA トマト,ピクルス,ベーコン ピザB トマト,ピクルス,パイナップル,チーズ ピザC トマト,焼き魚
>>> f(connection.queries) SELECT "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" SELECT ("app_pizza_toppings"."pizza_id") AS "_prefetch_related_val_pizza_id", "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE "app_pizza_toppings"."pizza_id" IN (1, 2, 3)
1つめのクエリでピザ(idが1,2,3)を取得した後に、2つめのクエリが発行されています。
ピザのIDをIN句で全て指定し、必要になるトッピングを全部あらかじめ取得するクエリです。 このクエリの結果をキャッシュしておき、上記のprintで必要になった時に利用しているイメージです。
表からは見えませんが、Pythonのコードによりキャッシュから該当部分を見つけています。
(補足) 上記の説明のソースはこちら。 QuerySet API リファレンス | Django ドキュメント | Django
No.4 Prefetchオブジェクトで多をfilter
prefetch_relatedは上記のようにキャッシュする仕組みです。
なので、キャッシュしたクエリとは異なるパターンでアクセスすると、むしろprefetch_relatedの分だけクエリが増えて無駄になります
以下の例は、アクセス時にfilterを使っています。この場合、prefetchした結果は利用されず再度SQLが発行されます。
- prefetch_relatedではallを指定.
- アクセス時にはfilterを指定.
for pizza in Pizza.objects.prefetch_related('toppings').all(): print(f'{pizza.name}', ','.join([t.name for t in pizza.toppings.filter(id__gte=3)])) ピザA ベーコン ピザB パイナップル,チーズ ピザC 焼き魚
>>> f(connection.queries) SELECT "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" SELECT ("app_pizza_toppings"."pizza_id") AS "_prefetch_related_val_pizza_id", "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE "app_pizza_toppings"."pizza_id" IN (1, 2, 3) SELECT "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE ("app_pizza_toppings"."pizza_id" = 1 AND "app_topping"."id" >= 3) SELECT "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE ("app_pizza_toppings"."pizza_id" = 2 AND "app_topping"."id" >= 3) SELECT "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE ("app_pizza_toppings"."pizza_id" = 3 AND "app_topping"."id" >= 3)
prefetchする子をフィルターする時は、Prefetchオブジェクトで指定します。
toppings側は、単にallを指定していますがきちんとフィルタされています。 この書き方は、allの結果を上書きしてしまうようなイメージです。
from django.db.models import Prefetch >>> reset_queries() >>> for pizza in Pizza.objects.prefetch_related(Prefetch('toppings', queryset=Topping.objects.filter(id__gte=3))): print(f'{pizza.name}', ','.join([t.name for t in pizza.toppings.all()])) ピザA ベーコン ピザB パイナップル,チーズ ピザC 焼き魚
>>> f(connection.queries) SELECT "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" SELECT ("app_pizza_toppings"."pizza_id") AS "_prefetch_related_val_pizza_id", "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE ("app_topping"."id" >= 3 AND "app_pizza_toppings"."pizza_id" IN (1, 2, 3))
to_attr属性を指定することで、Prefetchオブジェクトでカスタムしたキャッシュに明示的にアクセスできるので、こちらの記述方法がおすすめです。
>>> for pizza in Pizza.objects.prefetch_related(Prefetch('toppings', queryset=Topping.objects.filter(id__gte=3), to_attr='filtered_toppings')): print(f'{pizza.name}', ','.join([t.name for t in pizza.filtered_toppings]))
No.5 prefetch_relatedで2つ先のリレーション: ManyToMany-ManyToMany
ダブルアンダースコアで繋ぐことで指定できます。
- レストランをベースに、提供するピザとそのトッピングを全て取得する。
- レストラン↔️ピザ↔️トッピング
- レストランに紐つく全てのピザを取得する。
- ピザに紐つく全てのトッピングを取得する。
- レストランに紐つく全てのピザを取得する。
for restaurant in Restaurant.objects.prefetch_related('pizzas__toppings').all(): print(f'{restaurant.name}店のピザ一覧') for pizza in restaurant.pizzas.all(): print(f'\t{pizza.name}', ','.join([t.name for t in pizza.toppings.all()])) レストラン1店のピザ一覧 ピザA トマト,ピクルス,ベーコン ピザB トマト,ピクルス,パイナップル,チーズ レストラン2店のピザ一覧 ピザA トマト,ピクルス,ベーコン ピザC トマト,焼き魚
- prefetch_relatedなしなら各レストラン、各ピザごとにクエリが発生します。
- prefetch_relatedで以下の3つのクエリにまとまります。
- レストラン一覧の取得
- レストランのIDをIN句で指定し、対応するピザを全て取得。
- ピザのIDをIN句で指定し、対応するトッピングを全て取得。
>>> f(connection.queries)
SELECT "app_restaurant"."id", "app_restaurant"."name", "app_restaurant"."best_pizza_id" FROM "app_restaurant"
SELECT ("app_restaurant_pizzas"."restaurant_id") AS "_prefetch_related_val_restaurant_id", "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" INNER JOIN "app_restaurant_pizzas" ON ("app_pizza"."id" = "app_restaurant_pizzas"."pizza_id") WHERE "app_restaurant_pizzas"."restaurant_id" IN (1, 2)
SELECT ("app_pizza_toppings"."pizza_id") AS "_prefetch_related_val_pizza_id", "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE "app_pizza_toppings"."pizza_id" IN (1, 2, 3)
No.6 prefetch_relatedで2つ先のリレーション: ForeignKey-ManyToMany
※次のNo.7の劣化版です
No.5と同じく、ダブルアンダースコアで繋ぐことができます。FKで結合するモデルが間にあっても問題ありません。
- レストラン️←一番人気のピザ↔️トッピング
- レストランにFKで紐つく一番人気のピザ
- ピザに紐つく全てのトッピング取得
for restaurant in Restaurant.objects.prefetch_related('best_pizza__toppings').all(): print(f'{restaurant.name}店の一番人気のピザ') print(f'\t{restaurant.best_pizza.name}', ','.join([t.name for t in restaurant.best_pizza.toppings.all()])) レストラン1店の一番人気のピザ ピザA トマト,ピクルス,ベーコン レストラン2店の一番人気のピザ ピザC トマト,焼き魚
- prefetch_relatedなしなら各ピザごとにクエリが発生します。
- prefetch_relatedで3つのクエリにまとめることができます。
- レストラン一覧の取得
- レストランのIDをIN句で指定し、対応する一番人気のピザを取得(FKなので1件のみ)。
- ピザのIDをIN句で指定し、対応するトッピングを全て取得。
>>> f(connection.queries)
SELECT "app_restaurant"."id", "app_restaurant"."name", "app_restaurant"."best_pizza_id" FROM "app_restaurant"
SELECT "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" WHERE "app_pizza"."id" IN (1, 3)
SELECT ("app_pizza_toppings"."pizza_id") AS "_prefetch_related_val_pizza_id", "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE "app_pizza_toppings"."pizza_id" IN (1, 3)
No.7 prefetch_relatedで2つ先のリレーション: ForeignKey-ManyToMany + select_related
No.6の改善版です。ForeignKeyの部分は、prefetchよりselect_relatedを使ってSQLレベルで効率化する方が優れています。
主クエリ(select_relatedの"後"に事前読み込み(prefetch)が走るのをイメージすると分かりやすいです。
for restaurant in Restaurant.objects.select_related('best_pizza').prefetch_related('best_pizza__toppings').all(): print(f'{restaurant.name}店の一番人気のピザ') print(f'\t{restaurant.best_pizza.name}', ','.join([t.name for t in restaurant.best_pizza.toppings.all()])) レストラン1店の一番人気のピザ ピザA トマト,ピクルス,ベーコン レストラン2店の一番人気のピザ ピザC トマト,焼き魚
- 2つのクエリにまとめることができます。
- レストラン一覧 + 一番人気のピザ(FK)を同時に取得
- ピザのIDをIN句で指定し、対応するトッピングを全て取得。
>>> f(connection.queries) SELECT "app_restaurant"."id", "app_restaurant"."name", "app_restaurant"."best_pizza_id", "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_restaurant" INNER JOIN "app_pizza" ON ("app_restaurant"."best_pizza_id" = "app_pizza"."id") SELECT ("app_pizza_toppings"."pizza_id") AS "_prefetch_related_val_pizza_id", "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE "app_pizza_toppings"."pizza_id" IN (1, 3)
No.8 Prefetchで2つ先のリレーションをorder_byする
- レストラン↔️ピザ↔️トッピング: トッピングをnameの降順にする
- 中間にあるピザもprefetchされている点に注意(No.5をベースに考えます)
>>> for restaurant in Restaurant.objects.prefetch_related(Prefetch('pizzas__toppings', queryset=Topping.objects.order_by('-name'))): print(f'{restaurant.name}店のピザ一覧') for pizza in restaurant.pizzas.all(): print(f'\t{pizza.name}', ','.join([t.name for t in pizza.toppings.all()])) レストラン1店のピザ一覧 ピザA ベーコン,ピクルス,トマト ピザB ピクルス,パイナップル,トマト,チーズ レストラン2店のピザ一覧 ピザA ベーコン,ピクルス,トマト ピザC 焼き魚,トマト
- ピザIDをINに指定した、トッピング取得クエリにORDER_BYがつきます。
>>> f(connection.queries) SELECT "app_restaurant"."id", "app_restaurant"."name", "app_restaurant"."best_pizza_id" FROM "app_restaurant" SELECT ("app_restaurant_pizzas"."restaurant_id") AS "_prefetch_related_val_restaurant_id", "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" INNER JOIN "app_restaurant_pizzas" ON ("app_pizza"."id" = "app_restaurant_pizzas"."pizza_id") WHERE "app_restaurant_pizzas"."restaurant_id" IN (1, 2) SELECT ("app_pizza_toppings"."pizza_id") AS "_prefetch_related_val_pizza_id", "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE "app_pizza_toppings"."pizza_id" IN (1, 2, 3) ORDER BY "app_topping"."name" DESC
No.9 prefetch_relatedで2つ先のリレーション: ManyToMany-ForeignKey
No.7は、クエリ対象の直接の関連先がForeignKey、その先がManyToManyでした。 今回は直接の関連先がManyToManyで、その先にForeignKeyで結合したモデルがある場合です。
Pretetchで取得するとき、対象のFKをJOINさせる指示 というイメージが分かりやすいと思います。 Prefetchのquerysetでselect_relatedを使うのがポイントです。
- ピザ↔️レストラン←一番人気のピザ
- ピザ↔️レストラン: prefetchで別クエリにします(ピザIDをIN句指定)
- レストラン←一番人気のピザ: select_relatedでSQLで結合した状態で取得します。
for pizza in Pizza.objects.prefetch_related(Prefetch('restaurants', queryset=Restaurant.objects.select_related('best_pizza'))): print(f'{pizza.name}が提供されてるレストラン一覧') for restaurant in pizza.restaurants.all(): print(f'\t{restaurant}の一番人気のピザは: {restaurant.best_pizza.name}') ピザAが提供されてるレストラン一覧 レストラン1の一番人気のピザは: ピザA レストラン2の一番人気のピザは: ピザC ピザBが提供されてるレストラン一覧 レストラン1の一番人気のピザは: ピザA ピザCが提供されてるレストラン一覧 レストラン2の一番人気のピザは: ピザC
最初に取得したピザIDをIN句にしてまとめてレストランを一発で取れていることに注目してください。 さらに、それぞれのレストランの最良ピザはSQLの時点で結合できています。
>>> f(connection.queries) SELECT "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" SELECT ("app_restaurant_pizzas"."pizza_id") AS "_prefetch_related_val_pizza_id", "app_restaurant"."id", "app_restaurant"."name", "app_restaurant"."best_pizza_id", T4."id", T4."name", T4."country_id" FROM "app_restaurant" INNER JOIN "app_restaurant_pizzas" ON ("app_restaurant"."id" = "app_restaurant_pizzas"."restaurant_id") INNER JOIN "app_pizza" T4 ON ("app_restaurant"."best_pizza_id" = T4."id") WHERE "app_restaurant_pizzas"."pizza_id" IN (1, 2, 3)
省略しますが、prefetchなどをつけない状態だと以下のようにクエリがたくさん発行されます。 - ピザ一覧を取得し、それぞれのピザIDに対してレストランを1件ずつクエリで取得。 - そのレストランの最良ピザIDをクエリにして、再度ピザを取得する。
No.10 to_attrで複数の絞り込みをする
- 同じ対象を複数のパターンで同時に絞って使いたいケース。
- レストラン↔️ピザ で、ピザを複数の方法で絞る
- あるレストランにひもつく、イタリアのピザ一覧 と 全てのピザ一覧を同時に取得する。
余談ですが、italy_pizzaとall_pizzaを定義した時点ではSQLは発行されていないという点も大事です。 QuerySetは遅延評価なので、実際の値を取得するまで発行されません。
italy_pizza = Pizza.objects.filter(country=italy) all_pizza = Pizza.objects.all() for restaurant in Restaurant.objects.prefetch_related(Prefetch('pizzas', queryset=italy_pizza, to_attr='italy'), Prefetch('pizzas', queryset=all_pizza, to_attr='all_pizzas')): print(f'{restaurant.name}店') print('\t', ','.join([pizza.name for pizza in restaurant.italy])) print('\t', ','.join([pizza.name for pizza in restaurant.all_pizzas])) レストラン1店 ピザA ピザA,ピザB レストラン2店 ピザA ピザA,ピザC
Prefetchを指定した数だけ、SQLが増えます。
>>> f(connection.queries) SELECT "app_restaurant"."id", "app_restaurant"."name", "app_restaurant"."best_pizza_id" FROM "app_restaurant" SELECT ("app_restaurant_pizzas"."restaurant_id") AS "_prefetch_related_val_restaurant_id", "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" INNER JOIN "app_restaurant_pizzas" ON ("app_pizza"."id" = "app_restaurant_pizzas"."pizza_id") WHERE ("app_pizza"."country_id" = 1 AND "app_restaurant_pizzas"."restaurant_id" IN (1, 2)) SELECT ("app_restaurant_pizzas"."restaurant_id") AS "_prefetch_related_val_restaurant_id", "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" INNER JOIN "app_restaurant_pizzas" ON ("app_pizza"."id" = "app_restaurant_pizzas"."pizza_id") WHERE "app_restaurant_pizzas"."restaurant_id" IN (1, 2)
No.11 1つ先、2つ先のリレーションをそれぞれ条件付きでPrefetch(ManyToMany-ManyToMany)
- 1つ先のManyToManyをfilter条件付きでprefetchし、2つ先もfilterして取得するパターン.
- to_attrで名付けることで、2つ先をダブルアンダースコアで指定可能にします。
- 以下これまで記述した類似パターン
- No.5: all(1つ先)、all(2つ先)だった。
- No.8: all(1つ先)、2つ先をorder_by
- No.9: all(1つ先)、2つ先はselect_related
2つ先(トッピング)を取得する時に、すでにフィルタされた1つ先(ピザ)に関連するものだけ取得したい、というのがポイントです。
italy_pizza = Pizza.objects.filter(country=italy) for restaurant in Restaurant.objects.prefetch_related(Prefetch('pizzas', queryset=italy_pizza, to_attr='italy'), Prefetch('italy__toppings', queryset=Topping.objects.filter(id__lte=2), to_attr='topping_2')): print(f'{restaurant.name}店') for pizza in restaurant.italy: print(f'\t{pizza.name}', ','.join([t.name for t in pizza.topping_2])) レストラン1店 ピザA トマト,ピクルス レストラン2店 ピザA トマト,ピクルス
一つ先(Pizza)がレストランの取得結果とcountry=1でフィルタされている。 その結果のピザIDを3つめのtopping取得時にIN句で使い、id<=2のフィルタも同時に実行している。
>>> f(connection.queries) SELECT "app_restaurant"."id", "app_restaurant"."name", "app_restaurant"."best_pizza_id" FROM "app_restaurant" SELECT ("app_restaurant_pizzas"."restaurant_id") AS "_prefetch_related_val_restaurant_id", "app_pizza"."id", "app_pizza"."name", "app_pizza"."country_id" FROM "app_pizza" INNER JOIN "app_restaurant_pizzas" ON ("app_pizza"."id" = "app_restaurant_pizzas"."pizza_id") WHERE ("app_pizza"."country_id" = 1 AND "app_restaurant_pizzas"."restaurant_id" IN (1, 2)) SELECT ("app_pizza_toppings"."pizza_id") AS "_prefetch_related_val_pizza_id", "app_topping"."id", "app_topping"."name" FROM "app_topping" INNER JOIN "app_pizza_toppings" ON ("app_topping"."id" = "app_pizza_toppings"."topping_id") WHERE ("app_topping"."id" <= 2 AND "app_pizza_toppings"."pizza_id" IN (1))
2つ先をフィルタしないなら以下のように書けば良いです。
>>> for restaurant in Restaurant.objects.prefetch_related(Prefetch('pizzas', queryset=italy_pizza, to_attr='italy'), 'italy__toppings'): print(f'{restaurant.name}店') for pizza in restaurant.italy: print(f'\t{pizza.name}', ','.join([t.name for t in pizza.toppings.all()])) レストラン1店 ピザA トマト,ピクルス,ベーコン レストラン2店 ピザA トマト,ピクルス,ベーコン
No.12 親ベースで1件の子を取得する
- 子を、親モデル.get(検索条件)するようなケース
- 取得結果は1件でもList形式になり、これはどうしようもないっぽい。
- prefetchで指定し、0番目を取得する。
子側から検索して、関連する親をselect_relatedすることができるならそちらを採用する.
qtatsuの手順書
前書き
この記事は自分のブログ記事からの参照用です。 追記や変更を頻繁にする予定です。
1. Djangoの環境構築
前提
| バージョン | |
|---|---|
| MacOS Ventura | 13.5.2 |
| Python3 | 3.11.4 |
参考リンク
公式ドキュメントです.
- How to install Django | Django documentation | Django
- Writing your first Django app, part 1 | Django documentation | Django
手順
仮想環境の作成
$ python3 -m venv env $ source env/bin/activate # 完了確認 (env) $ python --version Python 3.11.4
以下、仮想環境中で作業します。(env)がついている状態です。
pipのアップデート
(env) $pip install --upgrade pip
Djangoのインストール
(env) $ pip install Django==5.0.1
プロジェクトの立ち上げ
projectというディレクトリを作成して、その中でstartprojectコマンドを実行します。
(env) $ mkdir project (env) $ cd project (env) $ django-admin startproject config . (env) $ ls config/ manage.py*
.を指定することで、manage.pyが今いるディレクトリ(project)にできるようになります。詳しくは以下のリンクを参考にしてください。
django-admin and manage.py | Django documentation | Django
アプリの追加
(env) $ python manage.py startapp app
設定ファイルのINSTALLED_APPSリストに以下を追記する.
INSTALLED_APPS = [
'app.apps.AppConfig', # 追加
...省略...
]
マイグレーション
$ python manage.py migrate
完了確認
$ python manage.py runserver 8000
指定したポートにアクセスします。 上記のように実行したのなら http://localhost:8000/ です。
ロケットのページが出ていたら成功です。
【Python】並び順を無視してlistの要素を比較する方法3つ【sort, assertCountEqual, deepdiff】
(※ qiitaに書いた記事の、削る前バージョンです)
【Python】並び順を無視してリストを比較するテスト(DeepDiff) - Qiita
- 結論: deepdiffを使う
- 前書き
- 参考リンク
- 環境
- 文字列のリスト: sortをつかう.
- 辞書のリスト: keyを指定してソートする.
- 辞書のリスト: assertCountEqualを使う.
- valueにリストをもつ辞書のリスト: DeepDiffを使う
- 結論
- まとめ
結論: deepdiffを使う
実現したい条件は以下の二つ.
- 辞書を要素として持つリストがあり、「同じリスト」かを比べたい.
- ただし並び順は異なっていても良いこととする。
- 辞書のあるvalue(下例では
spells)もリストとなっている。- こちらの要素も並び順は異なっていても良いこととする。
>>> dict_in_list1
[
{'name': 'Reimu', 'spells': ['Musouhuin', 'niju-kekkai']},
{'name': 'Marisa', 'spells': ['non-directional laser', 'star-dust reverie']},
{'name': 'Alice', 'spells': ['hourai-doll', 'shanghai-doll']}
]
>>> dict_in_list2
[
{'name': 'Marisa', 'spells': ['star-dust reverie', 'non-directional laser']},
{'name': 'Reimu', 'spells': ['Musouhuin', 'niju-kekkai']},
{'name': 'Alice', 'spells': ['hourai-doll', 'shanghai-doll']}
]
DeepDiffを使うと、以下のようにして同じデータであるかを比較できる.
pytest
assert not DeepDiff(dict_in_list1, dict_in_list2, ignore_order=True)
unittest
self.assertEqual(DeepDiff(dict_in_list1, dict_in_list2, ignore_order=True), {})
前書き
テストコードを書いていると、assert部分が巨大になってしまい、見通しや目的の把握が難しくなってくることがあります。
もちろん、なるべくテストを小さい単位で書く、クリティカルな部分のみチェックするなどの工夫をすることが第一ではあります。
しかし、APIの返り値やバッチ処理の結果などを、そのまま確かめたい..という以下のようなケースもあると思います.
- ある程度のデータの組みが揃うと意味の通るデータになるもの.
- テストを書きながら開発/リファクタしており、現在の返り値が壊れていないことを、リファクタ中に確かめるテストをサッと用意したい.
このようなケースでは、オブジェクトをそのまま比較したくなりますが、リストの要素を並び順を無視して比較するときは、要素の型によってとても難しくなってしまいます。
今回は、DeepDiffの他、sortする方法やassertCoutEqualメソッドを用いた方法も紹介したいと思います.
参考リンク
GitHub - seperman/deepdiff: Deep Difference and search of any Python object/data.
unittest --- ユニットテストフレームワーク — Python 3.10.0b2 ドキュメント
環境
| バージョン | |
|---|---|
| MacOS Big Sur | 11.6 |
| Python3 | 3.9.1 |
| deepdiff | 5.7.0 |
文字列のリスト: sortをつかう.
同僚の方はsortをよく使うとお聞きしました。
見た目にも何をやっているか分かりやすく、シンプルにかけるため、可能な限りこちらを使うべきだと思います .
文字列など、ソートできる(つまり<演算子で大小を比べることができる、__lt__が定義されている)場合は簡単です.
以下のふたつのリストを比較します。
含まれている要素は同じですが、順番が異なっていることに注意します。(同じ結果だと判定したい.)
names1 = ["Reimu", "Alice", "Marisa"] names2 = ["Reimu", "Marisa", "Alice"]
リストの比較は要素を頭から順番に比較するので、そのままではダメです.
>>> names1 == names2
False
ソートします。
>>> sorted(names1) == sorted(names2) True
辞書のリスト: keyを指定してソートする.
今度の例は辞書(dict)がリストの要素として並んでいます。
先ほどと似ていますが、今回はそのままではソートできません。
今回の例も、含まれている要素は同じですが、順番が異なっていることに注意します。(同じ結果だと判定したい.)
names1 = [
{"name": "Reimu"},
{"name": "Marisa"},
{"name": "Alice"},
]
names2 = [
{"name": "Alice"},
{"name": "Reimu"},
{"name": "Marisa"},
]
まず、そのまま比較したときはFalseとなります。(並び順は異なっていてもよいので, 実際はTrueだと判定したい)
>>> names1 == names2
False
dict同士は<の挙動が定義されていないのでsortできません。
>>> sorted(names1) TypeError: '<' not supported between instances of 'dict' and 'dict'
この場合、それぞれのdictが必ずname属性をもち、重複しないならば、keyを指定することでソートすることが可能です.
keyを指定すると、key: nameのvalueの値で比較してソートすることになります。
>>> sorted(names1, key=lambda x: x["name"]) [ {'name': 'Alice'}, {'name': 'Marisa'}, {'name': 'Reimu'} ]
keyに渡した関数lambdaの、引数xに各dictが順番に渡されます。そして、dictのnameキーにあたるvalueが取り出されて比較に使われるイメージです。
結果、順番に関係なく同じ要素を含んでいることが確かめられました.
>>> sorted(names1, key=lambda x: x["name"]) == sorted(names2, key=lambda x: x["name"]) True
keyで取得する値はタプルになっても良いので、nameキーだけではソートできない場合も対応できると思います(未検証)。
しかし、テストコードでの使用を想定している場合、結果の比較のために複雑なソート条件を書くことは慎重に考えた方が良いと思います。
辞書のリスト: assertCountEqualを使う.
このようなケースで、Python標準のツールにはもう一つ強力なものがあります。
unittestモジュールで、TestCaseクラスに実装されているassertヘルパーメソッドのひとつ、assertCountEqualです。
名前の印象とはかなり異なりますが、「順番によらず同じ要素が同じ数だけある」ことを検証できるassertメソッドとなっています。
unittest --- ユニットテストフレームワーク — Python 3.10.0b2 ドキュメント
unittestを使っている場合には、self.assertCountEqualを呼び出せば良いだけですので、今回はpytestなどからも使用できるよう、TestCaseをインスタンス化して使う手順を示します.
比較するのは、先ほどkey指定してソートしていたdict in listです。
names1 = [
{"name": "Reimu"},
{"name": "Marisa"},
{"name": "Alice"},
]
names2 = [
{"name": "Alice"},
{"name": "Reimu"},
{"name": "Marisa"},
]
>>> from unittest import TestCase >>> case = TestCase() >>> case.assertCountEqual(names1, names2) # OK!!
とても楽ですね!
公式ドキュメントに仕組みについて説明がありますが、ほとんどの組み込み型は何も意識せずに比較できます。自分の場合も、大抵の場合はsortとassertCountEqualのどちらかで事足りています。
assertEqual() メソッドは、同じ型のオブジェクトの等価性確認のために、型ごとに特有のメソッドにディスパッチします。これらのメソッドは、ほとんどの組み込み型用のメソッドは既に実装されています。さらに、 addTypeEqualityFunc() を使う事で新たなメソッドを登録することができます.
難点は今回の目的では、メソッド名称が不自然になる 点かと思います。
この名前は、仕組み自体をとてもよく表しています。出現したオブジェクトを、(collectionモジュールの)Counterを使って数え上げているためです。
なので「順番を気にせずリストを比較したい!」というのは、可能ではあるのですが本来の使い方とはちょっとずれているのかな、と思います。
多分ですが、assertCountEqualの本来の使い方は、下のようなケースだと思います。
>>> fruits1 = ["りんご", "みかん", "みかん", "りんご", "りんご"] >>> fruits2 = ["りんご", "みかん", "みかん", "りんご", "みかん"] >>> case.assertCountEqual(fruits1, fruits2) AssertionError: Element counts were not equal: First has 3, Second has 2: 'りんご' First has 2, Second has 3: 'みかん'
うーん、エラーメッセージも分かりやすいですね...!!!
valueにリストをもつ辞書のリスト: DeepDiffを使う
リストの比較は、大抵はsortedとassertCountEqualで可能かと思います。
というより、これ以上複雑な比較をするならそもそもテストの構成や比較の仕方を考え直した方がいいかと思います。
しかし、冒頭にも書きましたが、APIの返り値などを「実際に叩いてみて」とった値をそのままテストに使いたいというシーンが時々あります。
使い捨てのスクリプトをデグレしないように修正するときの一時的なテストコードを作る時などには、自分はこのようなassertを書きたくなります。
この場合、「リストの要素が辞書」かつ、「辞書のvalueにもリスト」があり、そのリストの順番も無視して要素が一致しているか確認したいケースがあります。
例を出すと、こんな感じです。
>>> dict_in_list1
[
{'name': 'Reimu', 'spells': ['Musouhuin', 'niju-kekkai']},
{'name': 'Marisa', 'spells': ['non-directional laser', 'star-dust reverie']},
{'name': 'Alice', 'spells': ['hourai-doll', 'shanghai-doll']}
]
>>> dict_in_list2
[
{'name': 'Marisa', 'spells': ['star-dust reverie', 'non-directional laser']},
{'name': 'Reimu', 'spells': ['Musouhuin', 'niju-kekkai']},
{'name': 'Alice', 'spells': ['hourai-doll', 'shanghai-doll']}
]
上の2つのリストは、要素であるdictの順番が入れ替わっています。
さらに、name: Marisaの項目を見ると、spells要素はリストなのですが、下に抜き出したように順番が逆になっています。
'spells': ['non-directional laser', 'star-dust reverie'] 'spells': ['star-dust reverie', 'non-directional laser']
これも含め、同一の物として判定したいです。
ちなみにassertCountEqualを使うと、以下のように異なる要素だと判定されてしまいます。
>>> case.assertCountEqual(dict_in_list1, dict_in_list2) AssertionError: Element counts were not equal: First has 1, Second has 0: {'name': 'Marisa', 'spells': ['non-directional laser', 'star-dust reverie']} First has 0, Second has 1: {'name': 'Marisa', 'spells': ['star-dust reverie', 'non-directional laser']}
このようなケースでも同じオブジェクトだと一発で判定できるサードパーティ製のライブラリがあります。それがdeepdiffです。
本来もっと多機能なのですが、今回はテストという観点のみから記述します.
導入はpipで簡単に行えます.
$ pip install deepdiff
今回のケース(リスト部分の順番を無視して同一かを判定)での使用は、以下のようにignore_order=Trueとしておこないます。
DeepDiff(dict_in_list1, dict_in_list2, ignore_order=True) {} # 空のdeepdiff.diff.DeepDiffオブジェクトが返ってくる.
あとは冒頭で示したように、assert文やassertメソッドで判定すればOKです。
なお、DeepDiffは差分がある場合には、どのキーのどの要素が、どんなふうに異なっているかを示してくれます。
>>> dict_in_list3 = [
{"name": "Marisa", "spells": ["star-dust reverie", "non-directional laser"]},
{"name": "Reimu", "spells": ["niju-kekkai"]},
]
>>> DeepDiff(dict_in_list1, dict_in_list3, ignore_order=True)
{
'iterable_item_removed': {
"root[0]['spells'][0]": 'Musouhuin',
'root[2]': {
'name': 'Alice',
'spells': ['hourai-doll', 'shanghai-doll']
}
}
}
dict_in_list3で削除された情報が、階層情報とともに表示されました.
結論
- 可能な限りsortedでソートして比較する.
- sort条件が複雑になるなら、assertCountEqualメソッドの使用も検討する.
- もっと難しい状況ではDeepDiffをignore_order=Trueとして使うこともできる.
まとめ
順番によらず、同じ要素を持つリストであるかを検証する方法を3つ紹介しました。
もちろん、そもそも比較しにくいものを比較せずに済むテストが書けるならその方がよいです。あまり乱用すると、返って読み辛いテストになってしまうかもしれません。
しかし特定の文脈では、今回紹介したような方法を試すのも選択肢に入れても良いのではないでしょうか.
他にもいい方法、自分ならこうするよ!などのご意見いただけると嬉しいです。
【Python】コミット差分のみblackで整形する 【darker】
前書き
コードの整形はフォーマッタに任せたいものです。
理想的には、全員が同じスタイルでコードを整形できるようにpre-commitなどを利用してコミット時にフォーマッタを自動実行します。
しかしプロジェクトの途中参加など、導入が難しいケースもあると思います。
今回の自分は、プロジェクトにフォーマッタが導入がされておらず
- せめて自分のコミット分だけはblackで整形したい。
- 共通ライブラリを更新時、ファイル単位ではなく行単位で整形したい。
という状況でした。 根本解決を諦め、次善の方法はないかと調べたところ darkerという、black(とisort)のwrapperライブラリが良さそうでした。
(なお、Darker作者はGitHubのREADMEに、本家のblackにも行単位のフォーマット機能は将来導入されそうだと言及しています.)
darkerについては日本語の情報が少ないようだったので、試してみた内容をまとめておこうと思います。
参考リンク
環境
| バージョン | |
|---|---|
| MacOS Big Sur | 11.6 |
| Python3 | 3.10.2 |
| darker | 1.3.2 |
| black | 21.12b0 |
| Pygments | 2.11.2 |
darkerのインストール
インストール
仮想環境を作ってpip installします。
$ python3.10 -m venv env $ source env/bin/activate
(env)$ pip install darker
注意: blackのバージョンを下げる必要がある.(2022-02-05) 修正されています.
(2022-03-04)追記: 現在は修正されています。この項目は不要ですが、記録として残しておきます。
2022-02-05 現在、このままだとdarkerを利用できません。
darkerはblackのwrapperなので、darkerをインストールすると最新のblackが一緒に落とされます。しかし、最新のblack(ついにβが取れた22.1.0)はdef find_project_root関数の返り値の型がPathからtupleに変わってしまい、darerは未対応です。
こちらのプルリクで、既にdarkerの作者(akaiholaさん)が修正中のようです。 追記: -> すでに修正されています。
とりあえずは、blackのバージョンをβ版まで落とせば良いです。
(余談ですが、以下のようにして実行するとinstall可能バージョンを見ることができて便利です.(多分正当な方法ではないですが...))
(env)$ pip install black== ............................(省略)........................... 20.8b1, 21.4b0, 21.4b1, 21.4b2, 21.5b0, 21.5b1, 21.5b2, 21.6b0, 21.7b0, 21.8b0, 21.9b0, 21.10b0, 21.11b0, 21.11b1, 21.12b0, 22.1.0) ERROR: No matching distribution found for black==
最新の一個前は21.12b0ですので、こちらにダウングレードしておきます。
(env)$ pip install black==21.12b0
Pygmentsで色をつける
もうひと手間加えて、出力結果の見た目をきれいにしておきます。
Pygments を同じ環境にインストールしてあると、darkerは出力結果をカラーにしてくれます。
(env)$ pip install Pygments==2.11.2
特に設定は必要ありません。
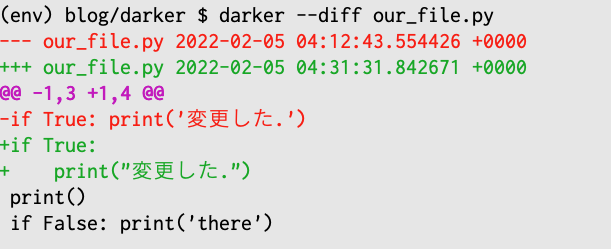
darkerの出力結果は、元々このような見た目ですが、
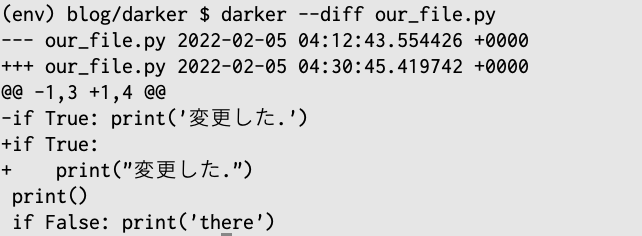
このように変わります。
使い方
新規差分を整形
まず、darkerはgit diffを利用するので、ディレクトリをgit 管理下におく必要があります。
適当なディレクトリを作成し、最初のコミットまで済ませておきます。(内容はなんでもOKです.)
$ git init $ touch README.md $ git add README.md $ git commit -m "first"
これでHEADができたので、darkerを利用できます。以下のようなpythonファイル(darker_test.py)を作成します。
(とにかく横に長くしたかっただけなので、適当です)
def format_name_and_age_to_profile(name: str | None, age: int | None, address: str | None): return f"{name} -- {age} -- {address}"
一旦、ここでコミットします. darkerが「コミット差分」に効くことを検証したいからです。
$ git add darker_test.py $ git commit -m "一つ目の関数" $ git log --oneline 7e25910 (HEAD -> master) 一つ目の関数 b6bee90 first
では、darker_test.pyにもう一つ記述を加えて以下のようにします。
def format_name_and_age_to_profile(name: str | None, age: int | None, address: str | None): return f"{name} -- {age} -- {address}" def format_name_and_age_to_profile_version_2(name: str | None, age: int | None, address: str | None): return f"{name} -- {age} -- {address}" # 2回目のコミット
まだコミットはしないでください! (addまではOKです.)
ここで darkerで修正差分を出力してみます.
今回は以下のように、カレントディレクトリ(.)かファイルを直接指定します。どちらでも結果は変わりません.
$ darker --diff . # カレントディレクトリ $ darker --diff darker_test.py # ファイル指定.

今回の変更分だけが整形されていることがわかります。 最初にコミット済みの、一つ目の関数は整形されていません。
また、この時点では元ファイルは変更されていません。修正をファイルに反映したければ、--diffオプションを外します。
$ darker .
整形後は以下のようになります。二つ目の関数(まだコミットしていない分)だけが、整形されています。
def format_name_and_age_to_profile(name: str | None, age: int | None, address: str | None): return f"{name} -- {age} -- {address}" def format_name_and_age_to_profile_version_2( name: str | None, age: int | None, address: str | None ): return f"{name} -- {age} -- {address}" # 2回目のコミット
では一旦コミットしておきましょう。
$ git add . $ git commit -m "二つ目の関数(整形済み)"
コミットを指定して整形
darkerはgit-diffを利用しているので、例えばあるコミットからあるコミットまでという範囲を指定し、その時の変更をターゲットに整形が可能です。
先程のコミットログは以下のようになっています。
$ git log --oneline 8de1f64 (HEAD -> master) 二つ目の関数(整形済み) 7e25910 一つ目の関数 b6bee90 first
一つ目の関数は整形できていなかったので、こちらを指定して整形を行います。firstコミット(b6bee90)から7e25910の間の変更なので以下のように指定します。
最後にPATHを指定する必要があるのですが、直接ファイル名(darker_test.py)を指定するか、以下のようにワイルドカードを使う必要がありました。
.(カレントディレクトリ)指定は、なぜかできない仕様のようでした。
$ darker --diff --revision b6bee90..7e25910 * # *.pyやdarker_test.pyでも大丈夫.
またhelpを見ると、コミット間は...(ドット三つ)で区切るように書いてありました。(2つでもできますが、違いは不明です)
結果は、指定したコミット間で記述した一つ目の関数が整形されています。

pre-commitでdarkerを使う
まずpre-commitの導入です。
(env)$ pip install pre-commit (env)$ pre-commit --version pre-commit 2.17.0
.pre-commit-config.yamlを Darkerの公式GitHubにある参考例を元に記述します。
blackのバージョンを落としてください (2022-02-06現在. 理由は前述の通り.)
repos: - repo: https://github.com/akaihola/darker rev: 1.3.2 hooks: - id: darker additional_dependencies: [black==21.12b0] # 最新blackだと失敗する.
$ pre-commit install
ではdarkerにまた長い名前の関数を1行で書き、実行してみます。
こちらを追記し...
def format_name_and_age_to_profile3(name: str | None, age: int | None, address: str | None): return f"{name} -- {age} -- {address}"
(env)$ git add . (env)$ git commit
結果、コミットしていない差分のみがフォーマットされているはずです。
そもそも自分だけコード整形することに意味はあるか?
同僚の方にも相談させていただいたのですが、
- そもそも自動フォーマットはレビューの負担軽減のためにやっている.
- チームでコードを統一することが目的.
という指摘をいただきました。
全くその通りで、本当はプロジェクト全体で設定ファイルを共有し、pre-commitでblack/isort/flake8/mypyあたりをかけることが自動フォーマットの目的に即していると思います。
自分の場合、
- 既存のpythonコードはフォーマッタなどを適応していない。また、クオートなどのスタイルはバラバラ。
- 新規にコードを追加するのは基本的に自分だけ。レビューは受ける.
- 既存のpythonスクリプトも、自前のutility関数が大量に入ったライブラリもそこそこの量がある。
という状況でした。
そのため、自分自身が書いた範囲のコードを読みやすくしたく、書くときには余計なことを考えなくて済むようにやはりフォーマッタは欲しいと思いました。そのため、本来の目的とは少し離れてしまうことを念頭に置き、一時しのぎ的にdarkerを利用しようと思っています。
もちろん、これは根本解決にはならない、ということを常に忘れないようにしたいと思います。
まとめ
- 可能ならプロジェクト立ち上げ時にpre-commitを設定しておいた方がよい。
- 自動フォーマットの目的は何か見失わないようにする。
- それでもコミット差分だけをフォーマットしたいなら、darkerは選択肢に入ってくる。
ご意見、ご指摘などいただけると嬉しいです:pray:
【Python】テスト時にデフォルト引数の値を差し替える
- 前書き
- 参考リンク
- 環境
- 前置き: テスト対象 なんどもリトライする関数
- テスト: 失敗するテストに時間がかかる
- 方法0. テストを分ける
- 方法1. __defaults__を書き換える
- 方法2. partialを使ってデフォルト引数を書き換える
- まとめ
前書き
この記事は
Calendar for JSL(日本システム技研) | Advent Calendar 2021 - Qiita
の12/13(月)の記事です。
Pythonのテストコードを書く時に、デフォルト引数を変更したいケースがあります。
たとえば失敗時にリトライを繰り返したり、ループを何周もする関数の挙動を確認する際には1,2回繰り返せば十分です。
関数呼び出し時に値を指定している場合は簡単にmockできますが、デフォルト引数の値をそのまま利用するケース、つまり関数呼び出し時に引数を指定していない場合には難しいです。
この記事ではその様なケースへの対処法を紹介しますが、「もっといい方法があるよ!」とか「そもそもこうした方がいいよ!」というご意見があれば、コメントでアドバイスいただけると嬉しいです。
参考リンク
unittest --- ユニットテストフレームワーク — Python 3.10.0b2 ドキュメント
unittest.mock --- モックオブジェクトライブラリ — Python 3.10.0b2 ドキュメント
functools --- 高階関数と呼び出し可能オブジェクトの操作 — Python 3.10.0b2 ドキュメント
環境
| バージョン | |
|---|---|
| MacOS Big Sur | 11.6 |
| Python3 | 3.9.1 |
| requests | 2.25.1 |
前置き: テスト対象 なんどもリトライする関数
今回テストする関数を見ていきます。
あくまでサンプルなので、実用コードとしては不十分です。お気をつけください。
main.py
import requests from requests.exceptions import ConnectionError def request_with_retry(url, retry=10): for i in range(retry): try: result = requests.get(url) except ConnectionError as e: print(f"失敗{i}回目") time.sleep(1) else: return result.content def show_result(url): content = request_with_retry(url) # デフォルトのretry数で実行 if content: return f"------- {content} ----------" else: return '結果を取得できなかった'
requests_with_retry関数
- 渡したURLにGETリクエストを投げ、結果のテキストを返す関数です。失敗したらNoneが返ります。
- 対象URLに接続できなくても、retry引数で渡した回数だけリトライを試みます。
- デフォルト値は10回です。
show_result
- テスト対象の関数です。
- 内部で
requests_with_retry関数をリトライ数を指定せず callし、その結果を利用しています。
では実際に動かし、挙動を確かめておきましょう。
IPythonをつかって、対話モードに入っています。
import main main.show_result("http://localhost:5000")
ローカルの5000ポートでは何もうごいていないため、以下の様に表示されます。
リトライするたびに1秒スリープしているため、実行に時間がかかります(gifなので実際より高速に見えますが)。
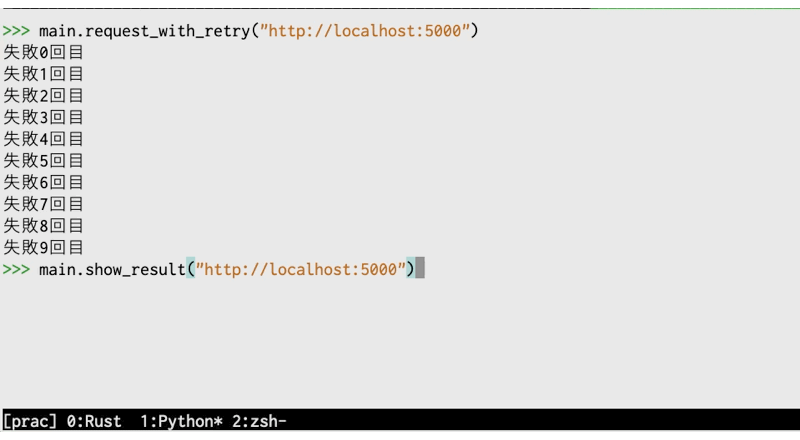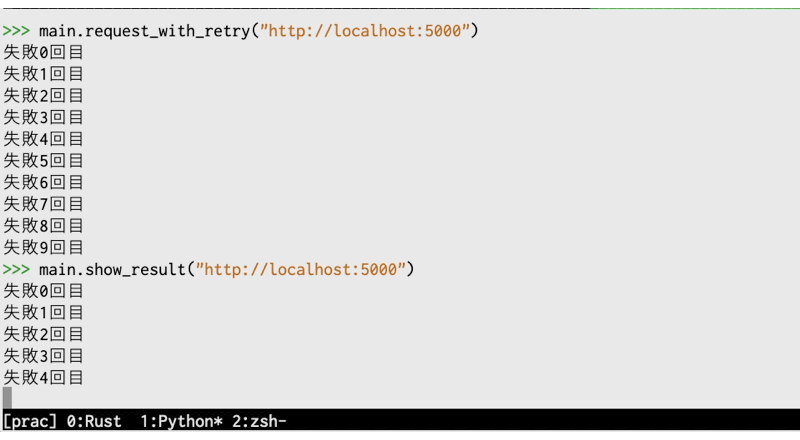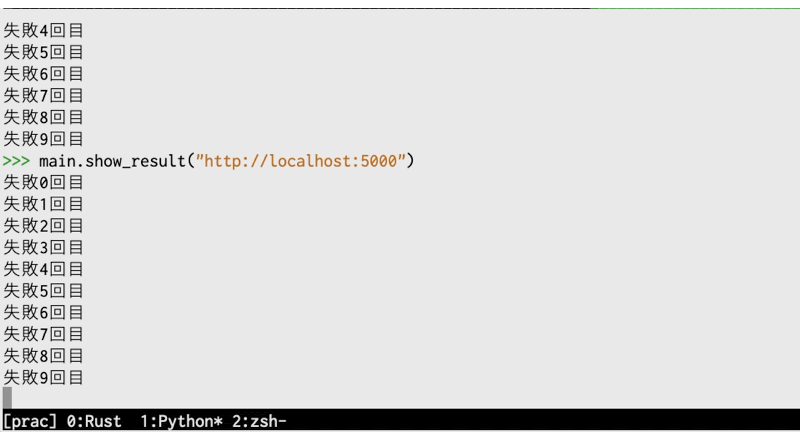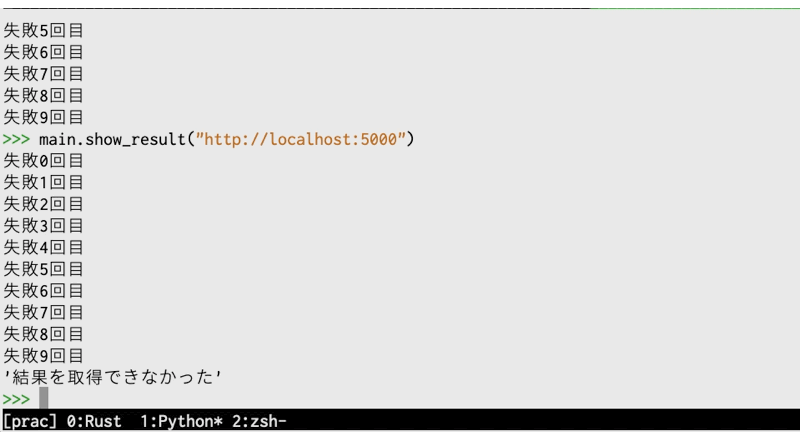
テスト: 失敗するテストに時間がかかる
さて、それではshow_result関数が結果を取得できないケースのテストを書いていきます。
実装をみると、失敗時には「'結果を取得できなかった'」という文字列を返すのでした。
main.pyに直接テストを書いていきます。今回はunittestを使います。
https://docs.python.org/ja/3/library/unittest.html
from unittest import TestCase class TestsMyFuncs(TestCase): def test_show_result_fail(self): url = 'http://localhost:5000' actual = show_result(url) self.assertEqual(actual, "結果を取得できなかった")
こちらを実行すると、以下の様になります。
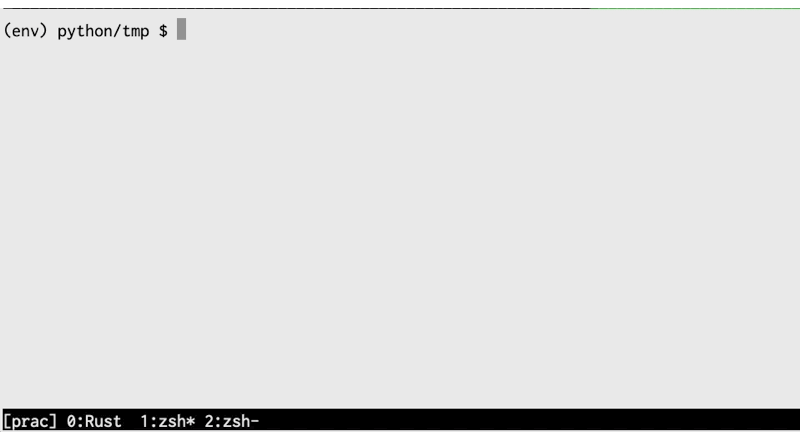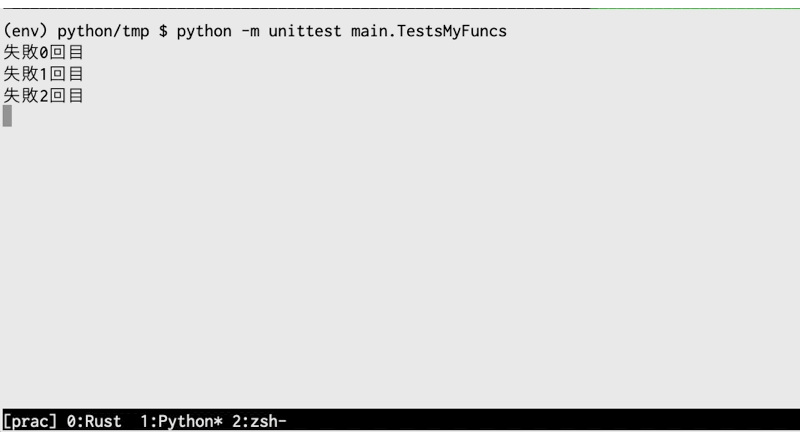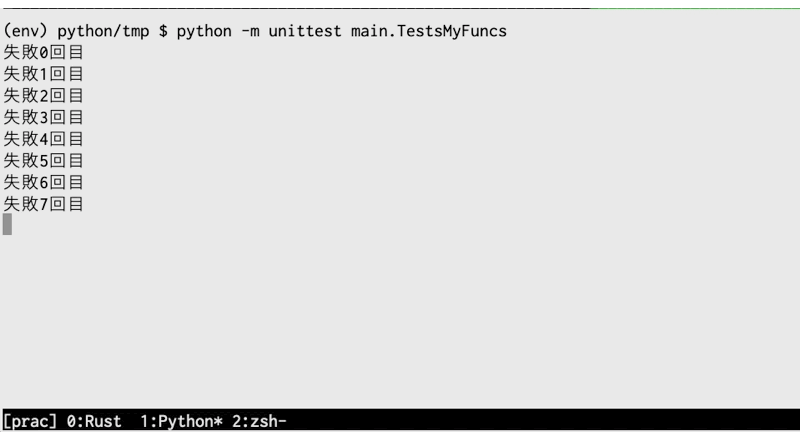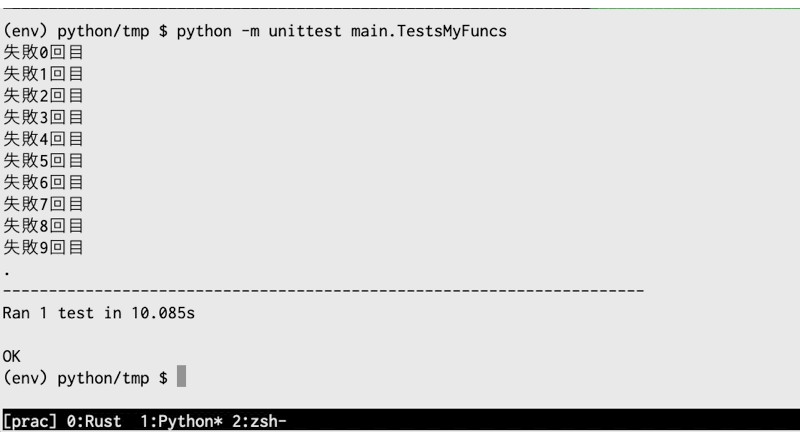
とても時間がかかっています.
単純に時間短縮するならsleepを短くするのも良いかもしれませんが、根本的な問題はリトライ回数のデフォルト値が大きすぎることだと思います。
というわけで、今回はこのデフォルト値を変更する方向で考えてゆきます。
方法0. テストを分ける
いきなりですが脱線します。
そもそも今回のケースは単純なので、テストを分割すれば解決する 問題だと思います。
show_resultは「request_with_retryを呼び、結果がNoneかテキストかによって別の文字列を返す」関数だといえます。
そうすると「URL→結果」を行うのはrequest_with_retry関数であり、このテストでチェックする必要はないです。丸ごとモックしてしまっても良い でしょう。
from unittest import TestCase, mock class TestsMyFuncs(TestCase): def test_show_result_fail(self): url = 'http://localhost:5000' with mock.patch('main.request_with_retry', return_value=None): actual = show_result(url) self.assertEqual(actual, "結果を取得できなかった")
テストを実行した結果です。
(env) python/tmp $ python -m unittest main.TestsMyFuncs . ---------------------------------------------------------------------- Ran 1 test in 0.001s OK
request_with_retryの機能(失敗したらNone, 成功したらcontentを返す)は、別のテストで確認すれば良いでしょう。
呼び出し時にリトライ回数を2回に制限します。
from unittest import TestCase, mock from requests.exceptions import ConnectionError class TestsMyFuncs(TestCase): # .......省略............ def test_request_with_retry(self): url = 'http://localhost:5000' with mock.patch.object(requests, 'get', side_effect=ConnectionError): actual = request_with_retry(url, retry=2) # ここでリトライ数変更 self.assertIsNone(actual)
テストを実行すると、リトライを2回だけ繰り返しています。
(env) python/tmp $ python -m unittest main.TestsMyFuncs.test_request_with_retry 失敗0回目 失敗1回目 . ---------------------------------------------------------------------- Ran 1 test in 2.002s OK
ユニットテストは可能な限り分割した方が役に立つし、変更にも強くなると思います。
方法1. __defaults__を書き換える
「方法0. テストを分ける」が可能なら良いのですが、そうは言ってられないケースもあると思います。
まずは デフォルト引数の値自体を書き換える ことにします。
まずは上記リンクで紹介されている、__defaults__を置き換える方法です。
上述のipythonで対話モードに入ります。
>>> import main >>> main.request_with_retry <function main.request_with_retry(url, retry=10)> >>> main.request_with_retry.__defaults__ (10,)
この様に、pythonのFunctionは__defaults__という属性にデフォルト引数で設定した値を持っています。
こちらを差し替えることでリトライ数を変更していきます。
差し替えにはmock.patch.objectを使うと便利だと思います。
unittest.mock --- モックオブジェクトライブラリ — Python 3.10.0b2 ドキュメント
class TestsMyFuncs(TestCase): def test_show_result_fail(self): url = 'http://localhost:5000' with mock.patch.object(request_with_retry, '__defaults__', (2, )): # 2回 actual = show_result(url) self.assertEqual(actual, "結果を取得できなかった")
テストを実行すると、リトライを2回だけ繰り返しています。
(env) python/tmp $ python -m unittest main.TestsMyFuncs 失敗0回目 失敗1回目 . ---------------------------------------------------------------------- Ran 1 test in 2.021s OK
方法2. partialを使ってデフォルト引数を書き換える
functools --- 高階関数と呼び出し可能オブジェクトの操作 — Python 3.10.0b2 ドキュメント
functoolsモジュールのpartial関数を使う方法です。
こちらは関数の引数に値を渡して、新しい関数を作るようなことができ、テスト以外でも役に立ちます。
実際にみた方が早いので、またまたipythonに入ってゆきます。
>>> import main >>> from functools import partial >>> modified = partial(main.request_with_retry, retry=1) # リトライ数を1に固定。 >>> modified('http://localhost:5000') 失敗0回目 # ここで終了している。
以上の様になります。modifiedは、request_with_retry関数のretryを1に固定した新しい関数...というイメージです。
では、テストコードを変更してゆきます。
from functools import partial class TestsMyFuncs(TestCase): def test_show_result_fail(self): url = 'http://localhost:5000' with mock.patch('main.request_with_retry', side_effect=partial(request_with_retry, retry=2)): actual = show_result(url) self.assertEqual(actual, "結果を取得できなかった")
テストを実行すると、リトライを2回だけ繰り返しています。
(env) python/tmp $ python -m unittest main.TestsMyFuncs 失敗0回目 失敗1回目 . ---------------------------------------------------------------------- Ran 1 test in 2.026s OK
自分はこちらの方法をよく使います。__defaults__の書き方と比べて、
- 読みやすい。
- partialは見た目からして「retry=2に書き換えている」というのがわかりやすいと思います。
__defaults__の方はコメントが必要でしょう。retryというパラメータと2が結びつきません。
- 調べやすい。
- partialのDocstringを読めば概要がわかります。
__defaults__のDocstringから、挙動を理解できるとは思えません。
まとめ
テストを分割できれば良いですが、時間の制約や実装を変更できないなどからデフォルト引数の値を変更したいケースが時々出てきます。
自分としてはpartialがおすすめです。
前書きにも書きましたが、
- もっと良い方法
- そもそも論
があればコメントいただけると嬉しいです!
watchdog、おまいだったのか。いつも、ファイルを監視してくれていたのは…【Python】
前書き
この記事はJSL(日本システム技研) Advent Calendar 2021のカレンダーの12/6(月)の記事です。
みなさん、watchdogというライブラリをご存知でしょうか。
watchdogは「番犬」「監視人」という意味があるようです。指定したフォルダ配下を監視し、ファイルの作成/変更/削除/移動イベントを感知してくれます。
他のライブラリからも利用されるため、お手元の環境でpip freeze | grep watchdogを実行すると出てくるかもしれません。
この記事では以下の観点からwatchdogを紹介したいと思います。
- 【watchdog】が使われているライブラリの紹介
- watchdogを自分でも使ってみよう!(サンプル)
参考リンク
Watchdog公式
- GitHub - gorakhargosh/watchdog: Python library and shell utilities to monitor filesystem events.
- Watchdog — watchdog 0.8.2 documentation
Flask, Werkzeug公式
pytest-watch公式
参考にさせていただいた記事
環境
| バージョン | |
|---|---|
| MacOS Big Sur | 11.1 |
| Python3 | 3.9.1 |
| watchdog | 2.1.6 |
| pytest | 6.2.5 |
| pytest-watch | 4.2.0 |
watchdogが使われているライブラリ
まずはwatchdogを利用しているライブラリを紹介します。
普段は意識しませんが、「勝手にリロードしてくれる」系の動作はwatchdogを使っていることがあります。(もちろん、自前で実装しているライブラリも多いですが).
Flask
Welcome to Flask — Flask Documentation (2.0.x)
Webアプリケーションフレームワークとして有名なFlaskです。
アイコンの画像が何物かわからないので、知っている人がいたら教えて欲しいです。(少なくともフラスコには見えないので、僕は勝手にシシトウだと思っています。)
Flaskには開発用サーバがついており、アプリケーションのファイルを編集すると、自動でサーバーがrestartして変更を反映するという機能を持っています。
こちらの公式ドキュメントにありますが、せっかくなので実際にやってみましょう。
- プロジェクト立ち上げ〜仮想環境にFlaskをインストール.
$ mkdir myproject $ cd myproject $ python3.9 -m venv env $ source env/bin/activate $ pip install --upgrade pip $ pip install Flask
sample.pyを作成し、以下のコードを記述します。
from flask import Flask app = Flask(__name__) @app.route('/') def gongitsune(): return 'ごん、おまいだったのか....'
- 環境変数を設定します。
FLASK_ENV=developmentがリロードを有効にする設定です。
$ export FLASK_APP=sample.py # 先程作成した.pyファイル. $ export FLASK_ENV=development # debugモード有効化
- 開発用サーバーを立ち上げます。
$ python -m flask run
さて、するとwatchdogがリロードをしてくれるはずですね!
sample.pyファイルを変更するとメッセージが出てきます。
.... * Restarting with stat ....
あれ?watchdogは...???
Flask公式ドキュメントのこの辺りを見ると、watchdogは自分でpip installする必要があると書かれています。
statはデフォルトでonになっているリローダです。watchdogの方がより高速で効率が良いとdocには書いてあります。
Watchdog provides a faster, more efficient reloader for the development server.
余談ですが、正確に言うとFlaskに使われているWerkzeugでstag/watchdogが採用されています。
Werkzeugは, WSGI準拠のアプリケーション作成を助けてくれるライブラリです。
Serving WSGI Applications — Werkzeug Documentation (2.0.x)
上記リンクによると、watchdogはstatよりリロードが速く、また効率についてはバッテリーの消費が少ないということらしいです。
前置きが長くなりましたが、リローダをstat→watchdogに切り替えてみましょう!
ドキュメントによると、pipでインストールすれば、自動でstatからwatchdogに切り替わります。
$ pip install watchdog
$ python -m flask run
.... * Restarting with watchdog (fsevents) ...
やりました。
小さなプロジェクトだとあまり変化は感じられませんが、topコマンドなどでCPU使用率などみてるとwatchdogの方が確かに低くなっていました(半分くらいになる)。
ちなみに同じく有名なWebフレームワークのDjangoにも自動リロード機能つきの開発サーバがついていますが、こちらは自前で実装しているようです。
以下のリンクがリロード用のモジュールのようですね(間違ってたらご指摘お願いします)。 django/autoreload.py at main · django/django · GitHub
pytest-watch
少し古いですが、ファイルを変更するたびにpytestを自動実行してくれる強力なライブラリです。
watchdogを使ったお手本のような例です。.pyで終わるファイルを検知してくれます。
以下のようなプロダクトコード/テストコードを書きます。
def heiju(text): return f"兵十「{text}」" def test_heiju(): text = "おまいだったのか" actual = heiju(text) assert actual == "兵十「{おまいだったのか}」"
以下のgifでは
- まず普通に
pytestでテストを実行しています。 - 次に、
ptwでテストを実行しています。コードを編集すると、自動で再度テストが走っています。

watchdogがファイルの変更を検知し、その度にpytestが走るというシンプルな仕組みですがかなり強力だと思います。
自分は小さなスクリプトを作る時や、ちょっと競プロに手を出していた時はこちらを使っていました。コードがめっちゃ速く書けます。
watchdogを自分でも使ってみる。
前置き: tmuxと一緒に使うのがオススメ.
画面分割→ 1画面でコード編集、1画面をwatchdogで監視...この形が一番捗ります。
自分はtmuxが好きなのでこちらをお勧めしますが、iTerm2を使ってる人も周りには多いですね。
こちらの記事がわかりやすいので、紹介させていただきます。 - tmuxを必要最低限で入門して使う - Qiita
例1: watchmedoでコマンドを登録してみる
まずはwatchmedoを使ってみましょう!
こちらwatchdogの公式製ツールで、以下のように追加インストールできます。
$ pip install "watchdog[watchmedo]"
パッと思いつくようなことは、大体コイツで可能です。
例えば以下のことをやってみましょう。
- jsonファイルが変更されたら、文法チェックをおこなう。
$ watchmedo shell-command \
-c 'python -m json.tool ${watch_src_path} > /dev/null'
-p '*.json'
--drop
まずはGIFをどうぞ。
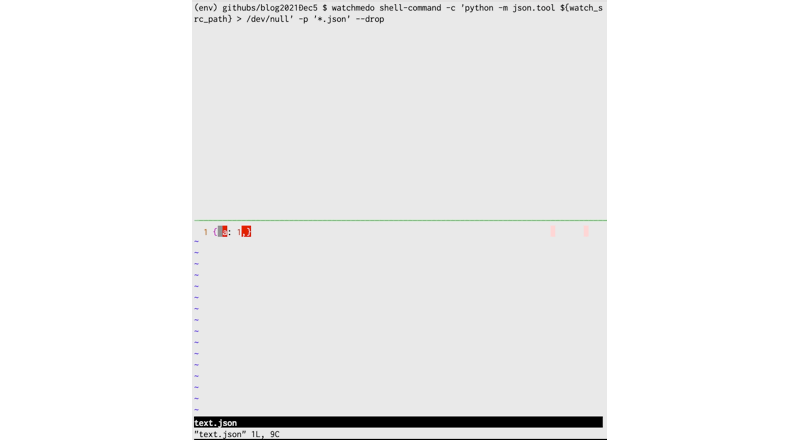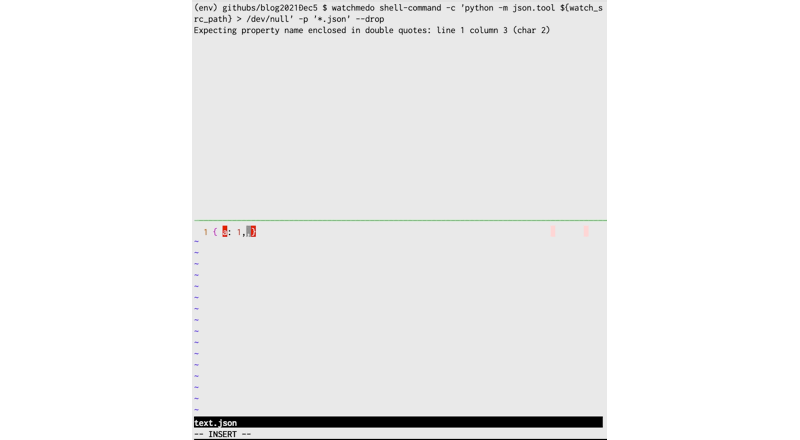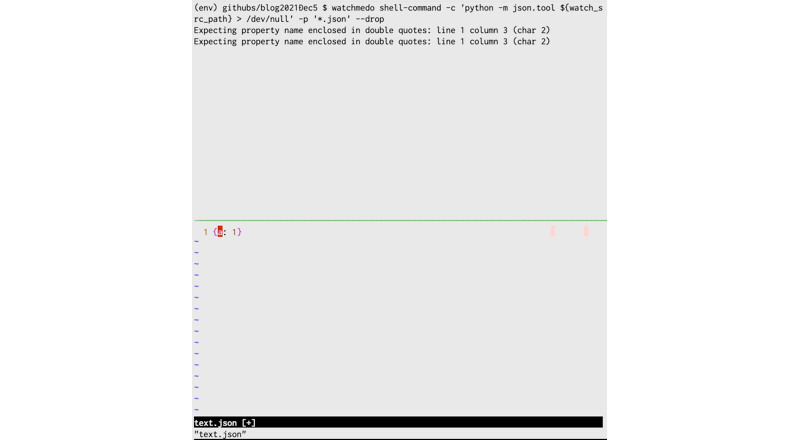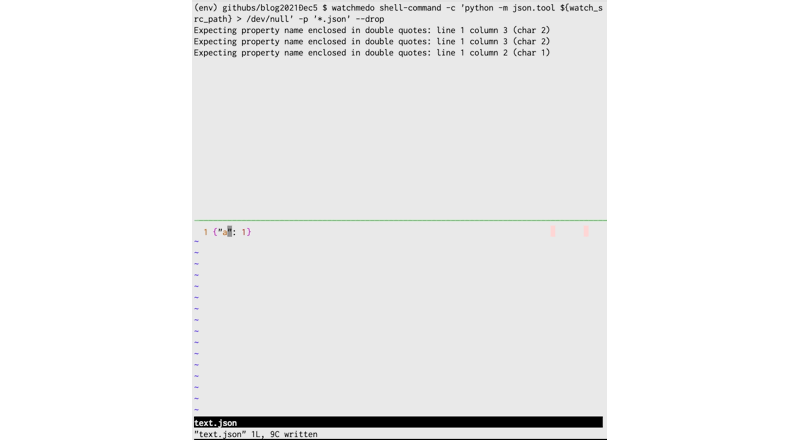
若干わかりづらいですが、:wというコマンドが画面一番下に出た瞬間、保存しています。
jsonをチェックしているコマンドはPythonの標準ライブラリで、jsonのフォーマッタです。標準出力を/dev/nullに捨てることでエラーチェックに使っています。
手前味噌ですがこちらの記事でも紹介しました。 シェル上でjsonをフォーマットする、各種ツール導入手順と使い方の個人的なまとめ
-cオプションで、ファイル変更イベント時に実行するコマンドを渡しています。${watch_src_path}は変更されたファイルのパスをフルパスで取得できます。
-pオプションで、変更を検知するファイル名のパターンを記述しています(今回はjson)--dropはイベントが複数回走らないようにしています。- これはvimのファイル変更方法が特殊なため、指定しています。他のエディタなら不要かと思います(未検証)
これらは以下のようにhelpを見ると、全てのオプションが説明されています。
$ watchmedo shell-command -h
ちなみに、コマンドを登録するshell-commandサブコマンドの他にも単純なlogを出したり、yamlを読ませて実行するサブコマンドもあります。
以下のようにして確認できます。
$ watchmedo -h
例2: ファイルの種類によって異なるコマンドを実行する!
このようなケースでは、yamlファイルに動作を定義して簡単に実行するサブコマンドが用意されています.
tricks-from というサブコマンドで、読み込むyamlファイルはtricsと呼ばれています。
また、以下の記事を参考にさせていただきました。
Python Watchdogのtricksを試す - Qiita
ではyamlを書いてみます。
tricks:
- watchdog.tricks.ShellCommandTrick:
patterns:
- "*.py"
shell_command: 'python ${watch_src_path}'
drop_during_process: true
- watchdog.tricks.ShellCommandTrick:
patterns:
- "*.json"
shell_command: 'python -m json.tool ${watch_src_path} > /dev/null'
drop_during_process: true
では、上記のtrics.yamlを指定してwatchmedoを実行してみます。
$ watchmedo tricks-from trics.yaml
pythonファイル編集→実行、jsonファイル編集→チェック、の順番でテストしています。
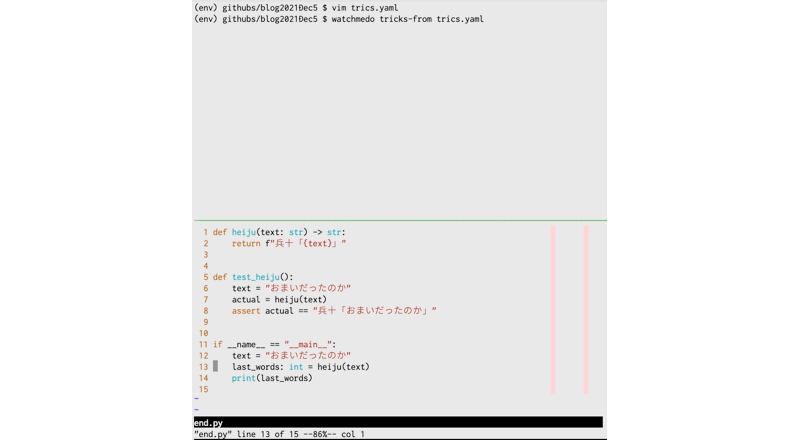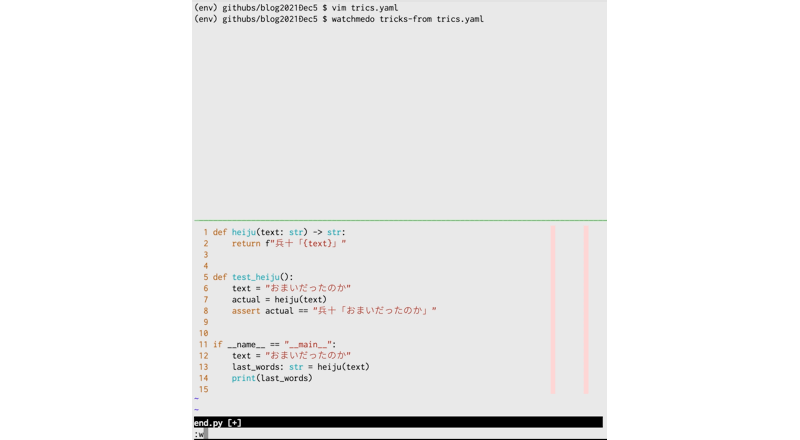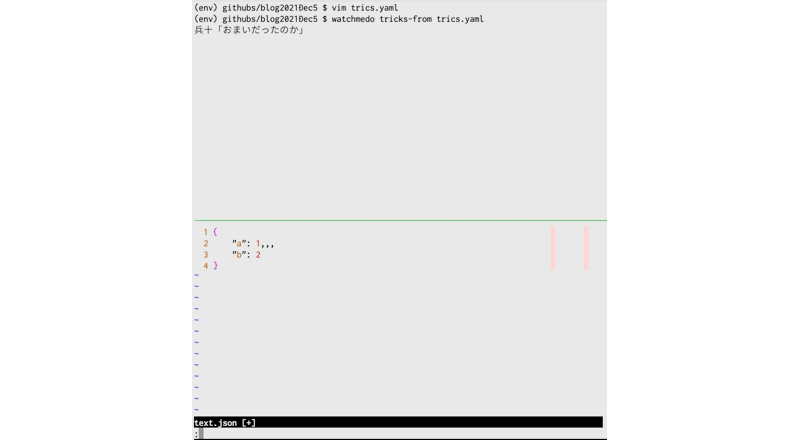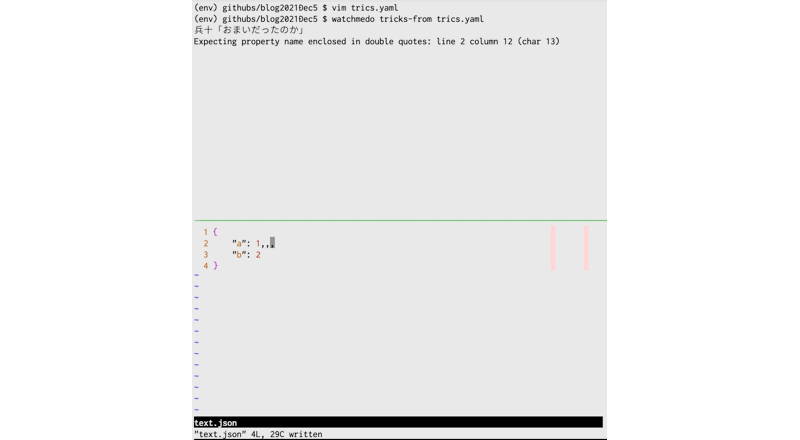
例3: 監視用スクリプトを実行する!
一番自由度が高い方法です。
Quickstart — watchdog 0.8.2 documentation
公式ドキュメントにもサンプルがあり、いろんな記事で紹介されているので、(機能的にはこちらメインですが)省略させていただきます。
以下、watchdogの利用例の記事を紹介させていただきます。
Pythonで変更のあったモジュールを動的インポート/リロードする - Qiita Pythonのwatchdogを使ってFTP受信ファイルを安全に処理する - Qiita Pythonのwatchdogを使ってFTP受信ファイルを安全に処理する - Qiita
まとめ
- watchdogを使うと、ファイル変更を監視することができる。
- watchmedoにより、ファイル変更-> コマンド実行やログ出しなどのよくあるパターンを簡単に実行できる。
- watchdogは他の便利なライブラリを支える、縁の下の力持ちとしても活躍している。
【Python】bytesとstrを真面目に理解する
前書き
本記事は、Pythonのbytes型およびエンコーディングの仕組みを「触って動かそう」方式で理解しよう!という内容です。
(strやbytesの詳しいメソッドなどは参考リンクの公式ドキュメントを参照していただきたいです。)
参考リンク
なんと公式ドキュメントにHOWTOがあります。僕の記事は要らなかったですね....
bytesやbytearray型についてはこちらを参照してください。
文字コード考え方から理解するUnicodeとUTF-8の違い | ギークを目指して
文字集合と文字コード、コードポイントについて、わかりやすく解説されています。
用語がいまいちわからない方はこちらから読まれることをお勧めします。
Unicodeとは? その歴史と進化、開発者向け基礎知識 - Build Insider
歴史的経緯から書かれており、分量は多いですがとても詳しい記事です。
Characters, Symbols and the Unicode Miracle - Computerphile - YouTube
エンコードの仕組みをASCII登場からUTF8まで、歴史的経緯とともに10分程度で説明されてます。公式のHOWTOの参考文献に載っていたのですが、お勧めなので紹介します。
環境
| バージョン | |
|---|---|
| MacOS Big Sur | 11.6 |
| Python3 | 3.9.1 |
bytesとは何なのか
結論: bytesはその名の通りバイト(10進数では0〜255)の集まり、整数の配列です。出力時には __repr__によりASCIIで表示されます。
1. 前置き: bytesは文字列の様に扱うことができる
bytes型(バイトオブジェクト)はbを文字の先頭につけて作成できます。(公式ドキュメントを見ると、この記法をバイトリテラルと呼んでいます)
>>> bytes1 = b'Hello, World!!' >>> print(bytes1) b'Hello, World!!'
bytesは普通の文字列(str型)と似ています。
例えば以下のように、strでお馴染みの結合と置換は、bytesでも可能です。
ただし、printした結果はバイトオブジェクトであることを表す"b"が付きます。
# 結合 >>> print(b'Hello, ' + b'World') b'Hello, World' # 置換 >>> b'Hello, World'.replace(b'Hello', b'Good night') b'Good night, World'
https://docs.python.org/3.9/library/io.html#binary-i-o
In-memoryのストリームとして、str型ではStringIOを使います。bytesはBytesIOストリームに渡すことができます。
>>> from io import BytesIO >>> buf = BytesIO() >>> buf.write(b'Hello, World!!') 14 >>> buf.tell() 14 >>> buf.seek(0) 0 >>> buf.read() b'Hello, World!!'
バイトリテラル記法では、非ASCII文字を渡すことはできません。
>>> b'ああ' SyntaxError: bytes can only contain ASCII literal characters.
2. bytesはその名の通り、バイト(整数)の配列
自分は学び初めの頃、上記のような「文字列の様な挙動」のイメージによって混乱していました。
bytesはその名の通り、1バイト=8ビット、つまり0〜255の整数が並んだ配列です。(二進数では0000_0000〜1111_1111)
バイトリテラル(b'')を利用せず、直接数値のリストからbytesを定義してみます。
組み込みのbytesクラスを使います。
※ ASCIIでは97, 98, 99にはa, b, cが対応します(wikipedia参照) ASCII - Wikipedia
>>> bytes([97, 98, 99]) b'abc'
bytesは数値の配列なので、sumで足し算することもできます(実用性はありませんが...)。
>>> sum(b'abc') # = 97 + 98 + 99 294
また、1バイトを超える数値を割り振ることはできません。
>>> bytes([255]) # OK b'\xff' >>> bytes([256]) # NG ValueError: bytes must be in range(0, 256)
ところで、先述したASCIIのwikipediaには以下のような記述があります。
ASCIIは、7桁の2進数で表すことのできる整数の数値のそれぞれに...(略) 初めの32文字(10進数で0-31)はASCIIでは制御文字として予約されている。基本的にはこれらの制御文字は表示するための文字ではなく、モニタやプリンタなどの機器を制御するために用いられる。
制御文字がどのように出力されるか、実際に試してみます。
>>> bytes([0, 1, 2, 30, 31, 32, 33]) b'\x00\x01\x02\x1e\x1f !'
32〜126は文字に変換できています。それ以外の数字だと、たとえ0-255の範囲でも文字に変換できていません。
制御文字(0〜31)は16進数表記で表されるようです。これはbytesの__repr__がそのように表現している、というだけの話だと思います(後述)。
32はスペース、33は"!"に対応しています。
次は126以上の数字を見てみましょう。
>>> bytes([126, 127, 128, 129, 255]) b'~\x7f\x80\x81\xff'
7bitで最大(111_1111)は127ですが、こちらは削除の制御記号とのことです(Wikipedia参照)。
3. bytesが文字列のように出力されるのは__repr__のため
bytesに数値の配列を渡してインスタンス化すると、バイトリテラルの形(b'')で結果が表示されました。
bytesの実体は整数の配列ですので、この挙動は __repr__特殊メソッドでASCII変換 した結果です。
__repr__を直接呼んでみましょう。(実用面での意味は全くありませんが...)
>>> bytes([97]).__repr__() "b'a'"
公式ドキュメントから一部を省略して引用します。
組み込み型 — Python 3.10.0b2 ドキュメント
bytesリテラルと repr 出力は ASCII テキストをベースにしたものですが、 bytes オブジェクトは、各値が 0 <= x < 256 の範囲に収まるような整数...(省略)... の不変なシーケンスとして振る舞います。...(省略)... 任意のバイナリデータが一般にテキストになっているわけではないことを強調するためにこのように設計されました
繰り返しますが、bytesの実体は整数の配列です。
list()を使って整数のリストに戻すこともできます.
>>> list(b'abc') [97, 98, 99]
もっと言うと、indexを指定して要素を取り出せます。結果はただの整数です。
>>> b'abc'[0] 97 # 余談ですが、slice記法で取り出すとbytes型のままです。 >>> b'abc'[0:1] b'a'
bytes型のメソッドや演算をみると、ASCIIコードで変換した文字列のように扱えます。しかしbytesの実体は整数です。
b'あ'のように非ASCII文字を渡せないのも、ASCIIで対応する数値が無いものは受け付けられないためです。
strとは何なのか
Unicode HOWTO — Python 3.9.4 ドキュメント 公式に記事があります。
1. 前置き: strはUnicode
まず、「PythonはUTF8で文字列を扱う」などと書かれている記事を散見しますが、これは誤りだと思います。 (僕が間違っていたらご指摘をお願いします:pray:)
open関数やstr.encode, str.decodeメソッドのデフォルト符号化方式としてUTF8が設定されているだけであり、文字列それ自体はUnicodeです。
換言すると、文字列を扱っている時点では符号化方式(UTF8やSJISなど)は関係ないですし、未定です。
符号化方式と文字集合の違いは、以下の記事がわかりやすかったので紹介させていただきます。
文字コード考え方から理解するUnicodeとUTF-8の違い | ギークを目指して
2. chrとord
組み込み関数ordは、strを受け取り(1文字のみ可)、対応するUnicodeのコードポイントを返します。
コードポイントは、ある文字集合(ここではUnicode)で、「その文字は頭から何番目か?」のような意味です。
下の例ではあのコードポイントを求めており、10進数では12354、16進数に変換すると0x3042であることがわかります(2バイト)。
>>> ord('あ') 12354 >>> hex(ord('あ')) '0x3042'
組み込み関数chrはordと逆の働きをします。
コードポイント(数値)を渡すと、そのコードポイントに対応する文字を返します。
>>> chr(12354) # 10進数で指定 'あ' >>> chr(0x3042) # 16進数で指定 'あ'
それでは、chrやord, その他エンコードのメソッドを使い、Pythonのstr型(Unicodeを表す)を色々触ってみます。
3. Unicodeの上限と\uエスケープ
Unicodeで一番大きなコードポイントの値は1_114_111(10進数)です。
1_114_112を渡すと範囲外となり、対応するものがないのでValueErrorになります。
>>> chr(1_114_111) '\U0010ffff' >>> chr(1114112) ValueError: chr() arg not in range(0x110000)
これは先程、bytesに255以上の値を渡した時とにています。
str型が持つ「1文字」も実体はコードポイントを表す数値です。
bytesほど単純ではないですが、ord関数を使えば数字(コードポイント)の配列に戻すこともできます。
ところで、\uエスケープを使うことで文字列リテラルの中で直接コードポイントを記述することもできます。
先程、あのUnicodeにおけるコードポイントは3042でしたので、"\u3042"は"あ"と全く同じということになります。
>>> "あ" == "\u3042" True
4. strとbytes: エンコードとデコード
これまでにも述べましたが、Pythonのstr(文字列)はUnicodeのコードポイントで表されています。
外部出力、たとえばファイルに書きこむ時には、UTF-8などの符号化方式でエンコードする必要があります。
逆に、エンコードされたファイルを読み込んで文字列として表示するには、デコードが必要です。
たとえばopen関数は、encoding引数で符号化方式を指定することができます。 UTF-8はデフォルトの符号化方式なので、特に指定しなければUTF-8となりますが、以下では明示的に指定しました。
# 書き込み >>> with open('tmp.txt', 'w', encoding='utf-8') as f: f.write('UTF-8だよ!!') # 読み込み >>> with open('tmp.txt', 'r', encoding='utf-8') as f: print(f.read()) # OUT: UTF-8だよ!!
文字列はエンコードされると、バイト列になります。
以下のように、エンコード/デコードをすることができます。
(str, bytesそれぞれのメソッドを使って変換していますが、他にもstr, bytesコンストラクタに渡したりcodecsを使う方法もあります: 省略)
>>> 'ぴた'.encode(encoding='utf-8') b'\xe3\x81\xb4\xe3\x81\x9f' >>> b'\xe3\x81\xb4\xe3\x81\x9f'.decode(encoding='utf-8') 'ぴた'
5. UnicodeとUTF-8 エンコードの仕組み
この章の本題です。
UTF-8の最初の方はASCIIと互換性がある
※ 理論の詳しい部分は、以下のブログまたは動画(10分くらい)がわかりやすいので参照していただきたいです。
(自分の記事では、Pythonを使って手を動かしながら挙動を確かめることに焦点を当てています.)
Unicodeとは? その歴史と進化、開発者向け基礎知識 - Build Insider
Characters, Symbols and the Unicode Miracle - Computerphile - YouTube
さて、日本語の文字列をutf-8でエンコードすると、バイト列が16進数表示で出力されていました。
ではアルファベットはどうなるでしょうか。
# 「あ」は 3バイト >>> 'あ'.encode('utf8') b'\xe3\x81\x82' # 「a」は[b'a']にエンコードされた。 >>> 'a'.encode('utf8') b'a'
バイトリテラル表記のb'a'になりました。
UTF-8では、0始まりの1バイト(つまり7ビット分)は完全にASCIIと互換性を持っています。
、0から始まる1バイト(0b_0000_0000〜0b_0111_1111、10進数では0〜127)はASCIIと同じコードポイントとなるのです。
ord関数を使って"a"のコードポイントを求めてみましょう。
>>> ord('a') # Unicodeのコードポイントを求める関数. 97 >>> bytes([97]) # ASCIIでも97番号は"a" b'a'
マルチバイト文字がエンコーディングされる様子を見てみよう
一方、日本語をUTF-8でエンコードすると、ひらがな一文字で3バイトの大きさのバイト列が出力されていました。
これは、UTF-8が可変長の文字コードとなっているからです。1バイトで表現し切ることができない文字は、複数バイトをつかってエンコードします。
その仕組みを詳しくみていきます。
まず、ひらがなの「あ」をエンコードした結果を2進数で表すと以下のようになります。
>>> 'あ'.encode('utf-8') # エンコード b'\xe3\x81\x82' >>> list(b'\xe3\x81\x82') # 10進数に変換 [227, 129, 130] >>> (bin(227), bin(129), bin(130)) # 2進数に変換 ('0b11100011', '0b10000001', '0b10000010')
わかりやすく、以降はハイフンで区切ります。
1バイト目が0b_1110_0011
2バイト目が0b_1000_0001
3バイト目が0b_1000_0010
となっています。
UTF-8では、文字の最初数bitをみるとそのバイトがどのような役割なのか分かるようになっています。
先程紹介したASCII互換の部分(1バイト文字)では、必ず0から始まります。逆に言えば、0から始まる1バイトはASCII互換の部分だとして解釈します。
そして1から始まる場合、
10xx xxxx-> マルチバイト文字の途中.110x xxxx-> 2バイトからなるマルチバイト文字の始まり1110 xxxx-> 3バイトからなるマルチバイト文字の始まり
このような意味になります。実際にやってみた方が早いので、「あ」のUnicodeコードポイントを手動で求めてみましょう。
- 1バイト目は
0b_1110_0011でした。- 1110 xxxパターンなので、3バイトからなることがわかります。
- ここで、「3バイト」を示す最初の
1110をのぞいた4bitを取り出します。1110_0011→0011
- 2バイト目は
0b_1000_0001でした。- 10xx xxxxパターンなのでマルチバイト文字の途中です。
- ここで、「途中」を示す最初の
10をのぞいた6bitを取り出します。1000_0001→00_0001
- 3バイト目は
0b_1000_0010でした。- 10xx xxxxパターンなので、これも2バイト目と同じです。
- 「途中」を示す最初の
10をのぞいた6bitを取り出します。1000_0010→00_0010
次に、1〜3バイト目から取り出したバイト列を結合します。
0011, 00_0001, 00_0010 を結合→ 0011_00_0001_00_0010
では、この結果をchr関数によってUnicodeのコードポイントとして解釈し、対応する文字を取り出します。
(※ Pythonでは0bを銭湯につければ2進数として扱うことができます)
>>> chr(0b_0011_00_0001_00_0010) 'あ'
文字「あ」が出力されました。 これで、「あ」をUTF-8でエンコードして得られたバイト列を手動で解釈し、Unicodeのコードポイントを取り出せたことがわかります。
まとめ
Pythonで「文字」を操作できるsrtやbytesだが、実体は数字の並びであることを意識すると仕組みがよく分かる。
- Pythonのbytes型はASCIIコードで変換された文字として出力されるが、実体は数値が並んだものである。
- Pythonのstr型は文字列をUnicode(文字集合)として扱っている。その実体はコードポイント(数字)
- UTF-8で文字列を符号化するとバイト列になる。
- 結果のバイト列は、コードポイント(数値)を特定のルールを元にバイト列で表現したものであった。
- ルールがわかれば、手動でもエンコードすることができる。
あとがき
以上です。自分がPythonを描き始めた頃に混乱したbytesやstr型の挙動をまとめました。
また、文字コードの仕組みについても実際にコードを動かして理解する助けになればいいな、という観点で紹介しました。
間違っている部分や不正確な部分などあれば、ぜひご指摘いただけると、とっても嬉しいです!!